Kubernetes管理者にとって、クラスタの健全性とパフォーマンスを把握することは欠かせません。Google Kubernetes Engine(GKE)にはcAdvisorとKubeletから有用なメトリクスを収集する仕組みが標準で備わっており、コンテナworkloadsの状態を詳しく可視化できます。本記事では、GKEでこれらのメトリクスを活用し、クラスタ内部の動きをより深く理解する方法を解説します。
cAdvisorとKubeletメトリクスとは
cAdvisorとKubeletは、Kubernetesエコシステムに欠かせないコンポーネントです。cAdvisorは、CPU、メモリ、ネットワーク使用量など、コンテナ内のリソース使用状況を継続的に監視します。一方、Kubeletはポッド内のコンテナのライフサイクルを管理します。両者から得られるメトリクスを組み合わせることで、クラスタのリソース消費とコンテナの健全性を総合的に把握できます。
GKEでcAdvisor/Kubeletメトリクスを監視するメリット
GKEでcAdvisor/Kubeletメトリクスの収集を有効化すると、次のようなメリットが得られます。
- クラスタの可視性向上: 各ポッドのリソース使用状況を詳しく把握でき、リソースの割り当てと最適化に活かせます。
- トラブルシューティングの効率化: コンテナworkloadsのボトルネックや異常を素早く特定し、問題解決までの時間を短縮できます。
- 先回りのキャパシティプランニング: 過去から現在までのリソース使用パターンを分析し、将来のスケーリング需要を予測できます。
GKEのマネージドサービスとして提供されているのか
はい、提供されています。GKE 1.29.3-gke.1093000 以降のバージョンでは、KubeletとcAdvisorのメトリクスをマネージド形式で収集できるオプションが用意されており、対象バージョン以降のクラスタであれば有効化するだけで利用できます。
以前のKubernetesバージョンを使っている場合は
GKE 1.29.3-gke.1093000 未満のバージョンでもメトリクスの収集自体は可能ですが、その場合は手動での設定が必要です。
OperatorConfigオブジェクトでスクレイピングを有効化し、collection.kubeletScraping.interval フィールドを設定します。
kubectl -n gmp-public edit operatorconfig config
apiVersion: monitoring.googleapis.com/v1
kind: OperatorConfig
metadata:
namespace: gmp-public
name: config
collection:
kubeletScraping:
interval: 30s
apiVersion: monitoring.googleapis.com/v1
kind: OperatorConfig
metadata:
namespace: gmp-public
name: config
collection:
kubeletScraping:
interval: 30s
詳細はこちらをご覧ください。
注意: すでにcAdvisor/KubeletメトリクスをGoogle Cloud Managed Service for Prometheusに取り込んでいる場合は、マネージド版のcAdvisor/Kubeletメトリクスを有効化する前に、既存の取り込みを必ず停止してください。停止しないままだと、メトリクスが重複したり不正確な値になったりするおそれがあります。
GKEでマネージドcAdvisor/Kubeletメトリクスを使い始める
押さえておきたいポイントは次のとおりです。
- 対応バージョン: 本機能は、バージョン 1.29.3-gke.109300 以降のGKEクラスタで利用できます。
- メトリクス収集の有効化: cAdvisor/Kubeletメトリクスの収集は、Google Cloudコンソール、gcloud CLI、Terraformのいずれからでも有効化できます。Google Kubernetes Engine APIを有効にし、監視したいcAdvisor/Kubeletコンポーネントを選択するだけです。Cloud Monitoringの構成を編集して、cAdvisorとKubeletのメトリクスを追加することもできます。
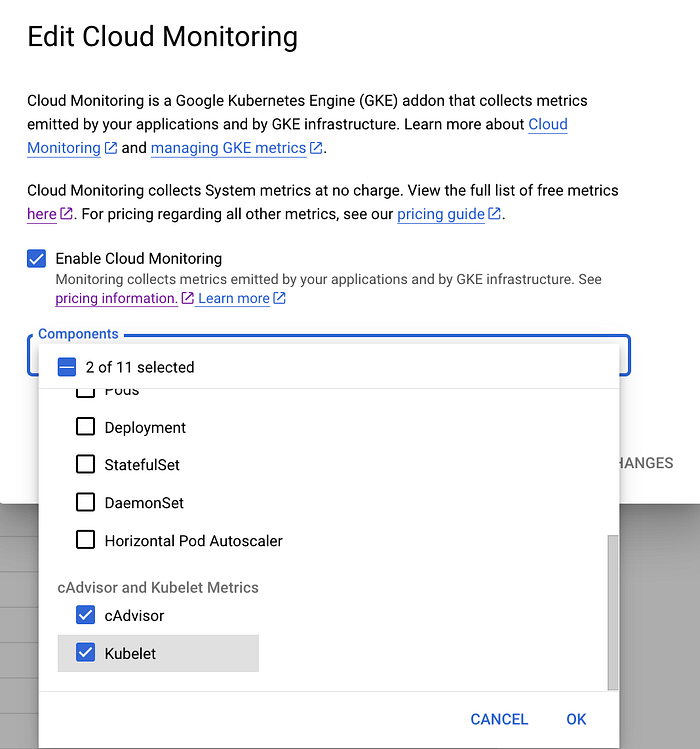
GKE Cloud Monitoringの編集画面
- メトリクスの確認: 有効化すると、メトリクスはGoogle Cloud Managed Service for Prometheusによって収集され、PromQLまたはMQLでクエリできます。Google CloudのMetrics Explorerでは、複数のターゲットを確認できます。
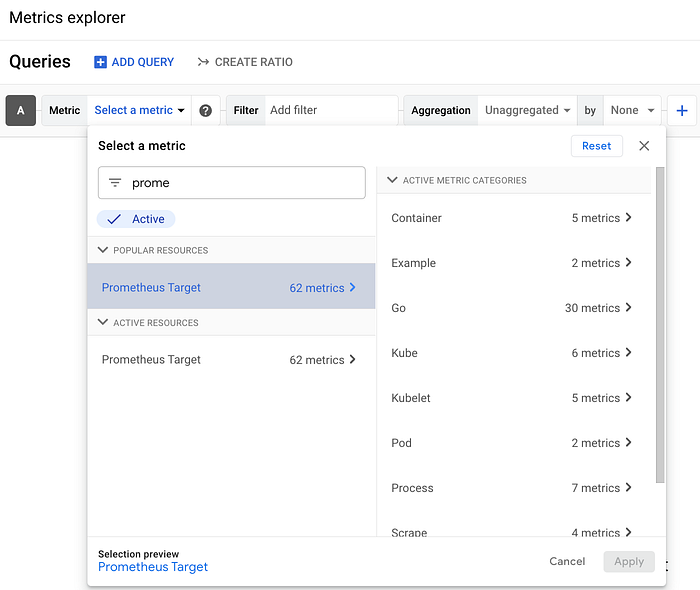
Google Cloud Metrics Explorer
特に役立つメトリクスのひとつが container_cpu_usage_seconds_total です。コンテナのCPU使用量を確認できるため、VPAをレコメンダーとして使わなくても、CPUのrequestsとlimitsを適切に設定できます。例:
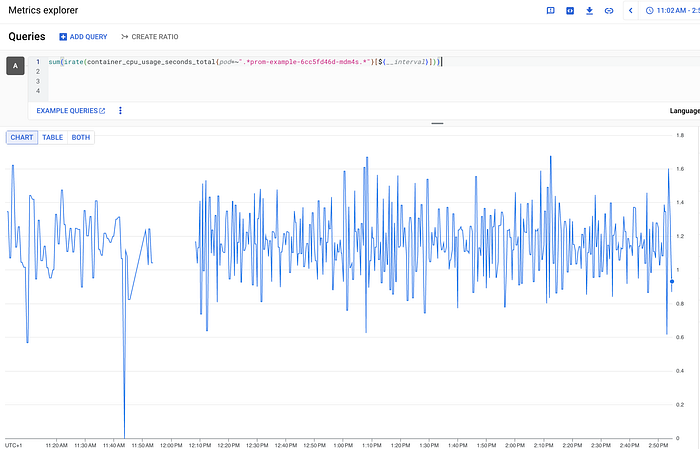
GCP Metrics Explorer: container_cpu_usage_seconds_total
GKEでcAdvisor/Kubeletメトリクスを活用すれば、クラスタのリソース使用状況をより深く理解できます。これらのデータは、パフォーマンスの最適化、潜在的な問題の早期発見、そしてコンテナ化されたアプリケーションの効率的な運用に大きく貢献します。GKEのマネージドcAdvisor/Kubeletメトリクスを使えば、その実現はぐっと手軽になります。
参考リソース:
https://cloud.google.com/stackdriver/docs/managed-prometheus/exporters/kubelet-cadvisor
https://github.com/google/cadvisor
https://cloud.google.com/kubernetes-engine/docs/release-notes-new-features#June_07_2024
https://cloud.google.com/stackdriver/docs/managed-prometheus
DoiT Internationalをまだご存じない方は、ぜひ一度ご覧ください。私たちのチームは、お客様のクラウドエンジニアリングの課題にじっくり向き合います。シニアクラスのEngineersのみで構成されており、高度なクラウドコンサルティング、アーキテクチャ設計、デバッグに関する助言を専門としています。お気軽にお問い合わせください。