

Cuando te enfrentas a un problema crítico de infraestructura en la nube, cada segundo cuenta. Necesitas ayuda rápido, y necesitas que sea precisa. Pero incluso cuando no tienes prisa, no quieres perder tu valioso tiempo rellenando largos formularios; quieres describir tu problema y que se encarguen del resto.
El reto: hacer que la asistencia asistida por IA sea más ágil e interactiva
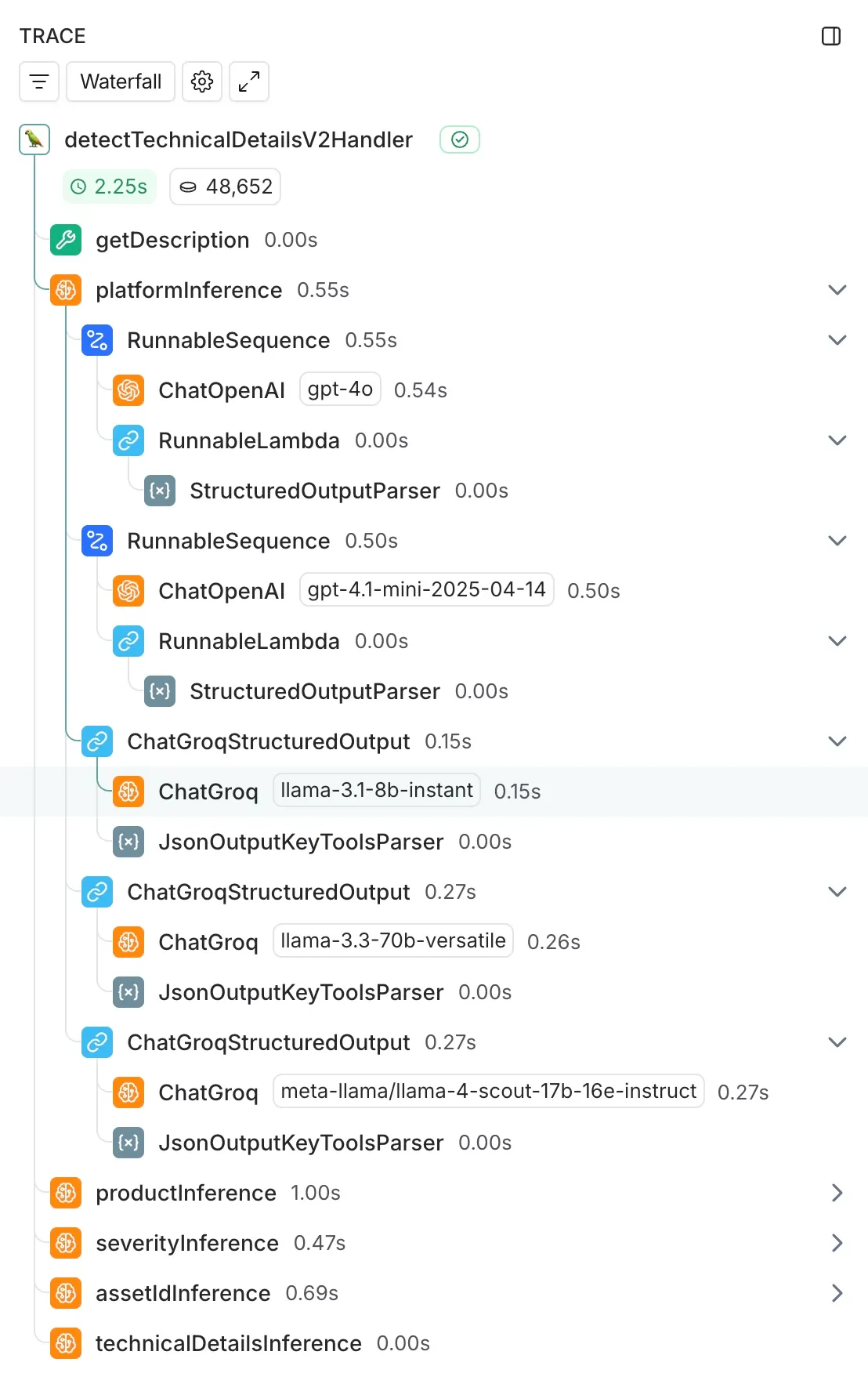
En DoiT, tenemos a Ava para ayudarte con tus consultas sobre FinOps y la nube. A veces, sin embargo, quieres hablar las cosas con un experto humano. Es entonces cuando nuestro sistema Case IQ ayuda a los clientes a proporcionar los detalles técnicos correctos al abrir un caso, garantizando que nuestros Ingenieros de Fiabilidad del Cliente (CRE) tengan todo lo que necesitan para resolver los problemas rápidamente.
La idea surgió en nuestro hackathon del verano de 2024 y se basó en las API de OpenAI. Sin embargo, decidimos superar el status quo y hacerlo mejor, centrándonos en la latencia de nuestras recomendaciones al cliente, haciendo que el sistema pareciera más ágil e interactivo.
El Experimento: probar cinco modelos de latencia, coste y rendimiento
Para resolverlo, diseñamos un experimento exhaustivo de 2 semanas en el que comparamos nuestro modelo actual ( GPT-4o de OpenAI) con cuatro alternativas:
- GPT-4.1 mini (el modelo más nuevo y rápido de OpenAI)
- Llama 3.1 8B (modelo más pequeño y ultrarrápido en el hardware especializado de Groq)
- Llama 3.3 70B (modelo más grande y capaz en Groq)
- Llama 4 Scout 17B (modelo preliminar de la última familia de modelos de Meta con capacidades prometedoras)
El objetivo principal era encontrar un modelo con latencias más bajas que la referencia GPT-4o. Para conseguirlo, esperamos sufrir un (pequeño) impacto en la calidad de la respuesta, y aceptar cualquier reducción de costes como un agradable efecto secundario.
Hemos probado estos modelos en cinco tareas que Case IQ realiza cuando creas un compromiso:
- Detección de plataforma: Con qué plataforma concreta está relacionada la petición
- Identificación del producto: ¿Qué servicio en la nube concreto necesita ayuda?
- Evaluación de la gravedad: ¿Hasta qué punto es urgente este problema?
- Identificación de activos: ¿Qué proyecto o cuenta está afectado?
- Extracción de detalles técnicos: ¿Qué información específica necesitan nuestros ingenieros?
Durante dos semanas, procesamos 21.517 trazas de 755 interacciones con clientes reales, midiendo la latencia, el coste y la precisión.
La base técnica que facilitó esta comparación fue nuestra integración LangChain existente. Como ya utilizábamos LangChain para nuestra implementación de GPT-4o, añadir los modelos de comparación fue sencillo: añadimos llamadas a ChatGroq junto a nuestra integración ChatOpenAI existente, ejecutándolas de forma asíncrona para evitar que afectaran a nuestro sistema de producción.
Utilizamos LangSmith para una instrumentación exhaustiva, capturando automáticamente medidas de latencia, uso de tokens, tasas de error y registro de entrada/salida en todas las trazas.
Los resultados: mayor velocidad a cambio de un pequeño sacrificio de calidad
Los resultados superaron nuestras expectativas:
⚡ Mejoras de velocidad de 4-5x
- Detección de plataforma: 571ms → 249ms (4,1x más rápido, usando Llama 3.3 70B)
- Detección de productos: 851ms → 406ms (2,1x más rápido, usando Llama 3.1 8B)
- Detección de gravedad: 605ms → 126ms (2,6 veces más rápido, utilizando Llama 3.3 70B)
- Detección de activos: 593ms → 220ms (2,7 veces más rápido, usando Llama 3.3 70B)
- Detalles técnicos extracción: 1.914 ms → 334 ms (5,7 veces más rápido, utilizando Llama 3.1 8B)
💰 Hasta 50 veces menos costes
Aunque la velocidad era nuestro principal objetivo, el ahorro de costes fue notable: algunas tareas pasaron a ser 50 veces más baratas de ejecutar manteniendo la calidad.
🎯 Mantener el rendimiento
Mediante la revisión manual de compromisos con clientes reales, descubrimos que mientras GPT-4o alcanzaba una precisión del 92-96%, nuestras alternativas más rápidas mantenían un fuerte rendimiento:
- Llama 3.3 70B: 88-96% de precisión con mejoras de 2-3x en la velocidad
- Llama 3.1 8B: 55-88% de precisión con mejoras de velocidad de 4-5x
La Estrategia Ganadora: Un enfoque híbrido
En lugar de elegir un único modelo "mejor", llegamos a la conclusión de que se necesitaban distintos modelos para obtener una solución global óptima:
- Llama 3.1 8B para la detección de productos y detalles técnicos (dado que estas tareas tienen dependencias entre sí, aquí es donde más importa la velocidad)
- Llama 3.3 70B para la detección de plataformas y gravedad, y la identificación de activos (Llama 3.1 8B parecía tener dificultades con esta tarea, aunque creemos que hay margen de optimización mediante avisos).
¿El resultado? El tiempo total de respuesta baja de más de 3 segundos a menos de 1 segundo: una aceleración global de 3-4 veces. Además, con este enfoque híbrido, esperamos un ahorro de costes de ~93% en nuestra factura total.
Qué significa esto para ti
⚡ Respuestas casi instantáneas: Cuando describes tu problema de infraestructura en la nube, CaseIQ puede ahora analizarlo y solicitar los detalles técnicos correctos casi al instante.
🔄 Canales de soporte en tiempo real: Estas mejoras en la velocidad abren nuevas posibilidades. Estamos explorando la posibilidad de poner el soporte directamente en Slack u otras plataformas de mensajería en las que ya están presentes nuestros clientes.
🚀 Mejor resolución a la primera: Las descripciones de problemas más precisas y completas para nuestros especialistas conducen a tiempos de respuesta más rápidos y reducen las idas y venidas.
Conclusiones y próximos pasos
Aunque todos los detalles técnicos son fascinantes (y están disponibles aquí), el aprendizaje clave fue doble:
- La selección estratégica de modelos funciona: Una cuidadosa selección del proveedor y del modelo, combinada con decisiones arquitectónicas inteligentes, puede conseguir mejoras drásticas de la latencia (de más de 3 segundos a menos de un segundo) y, además, una reducción masiva de los costes.
- La evaluación humana es insustituible: Aunque las métricas automatizadas proporcionan líneas de base útiles, la revisión manual sigue siendo esencial para comprender el rendimiento real cuando se trata de texto y seres humanos; siempre hay matices que sólo las personas pueden evaluar adecuadamente.
En DoiT, creemos en ser "impulsados por la tecnología, perfeccionados por las personas". Estas mejoras garantizan que cuando necesites la experiencia humana de nuestros CRE, nuestra IA ya ha hecho el trabajo preliminar para darte respuestas lo más rápidamente posible.
-
¿Quieres experimentar por ti mismo la mejora de Case IQ? Habla hoy con nosotros y descubre cómo podemos ayudarte.



