Bei einem kritischen Cloud-Infrastruktur-Problem zählt jede Sekunde. Sie brauchen schnelle und präzise Hilfe. Aber auch wenn es nicht brennt, möchten Sie Ihre Zeit nicht mit dem Ausfüllen langer Formulare vergeuden. Sie wollen Ihr Problem schildern – um den Rest soll sich jemand anderes kümmern.

Latenz und Kosten gleichzeitig senken? Da sind wir dabei!
**Die Herausforderung: KI-gestützten Support schneller und interaktiver machen**
Bei DoiT unterstützt Sie Ava bei FinOps- und Cloud-Fragen. Manchmal möchten Sie aber direkt mit einem menschlichen Experten sprechen. Genau hier kommt unser Case-IQ-System ins Spiel: Es hilft Kunden, beim Anlegen eines Tickets gleich die richtigen technischen Details mitzuliefern, damit unsere Customer Reliability Engineers (CREs) sofort alles haben, was sie zur schnellen Lösung brauchen.
Die Idee entstand bei unserem Hackathon im Sommer 2024 und wurde auf Basis der OpenAI-APIs umgesetzt. Wir wollten uns mit dem Status quo aber nicht zufriedengeben, sondern nachlegen – vor allem bei der Latenz unserer Empfehlungen, damit sich das System spürbar flotter und interaktiver anfühlt.
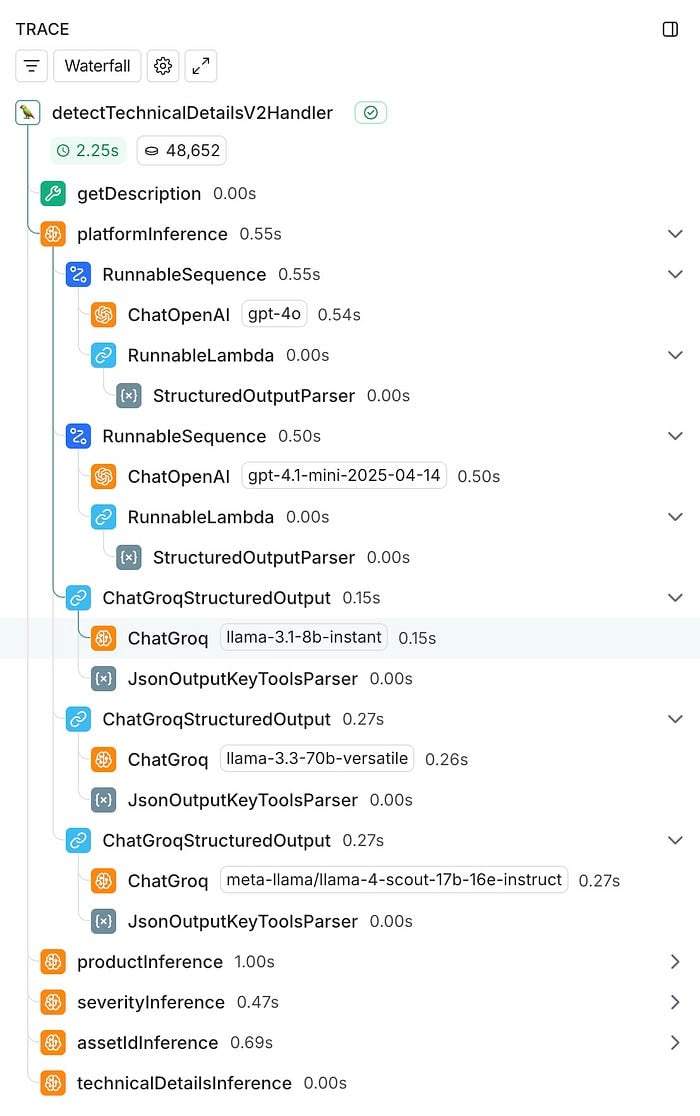
**Das Experiment: fünf Modelle im Test auf Latenz, Kosten und Performance**
Dazu haben wir ein umfassendes zweiwöchiges Experiment aufgesetzt und unser bisheriges Modell (OpenAI GPT-4o) gegen vier Alternativen antreten lassen:
- GPT-4.1 mini (das neuere, schnellere Modell von OpenAI)
- Llama 3.1 8B (kleineres, ultraschnelles Modell auf Groqs spezialisierter Hardware)
- Llama 3.3 70B (größeres, leistungsfähigeres Modell auf Groq)
- Llama 4 Scout 17B (Preview-Modell aus Metas neuester Modellfamilie mit vielversprechenden Fähigkeiten)
Hauptziel war es, ein Modell mit niedrigerer Latenz als die GPT-4o-Baseline zu finden. Dass wir dafür kleine Abstriche bei der Antwortqualität in Kauf nehmen müssen, war eingeplant – mögliche Kostenersparnisse waren ein willkommener Nebeneffekt.
Getestet haben wir die Modelle anhand von fünf Aufgaben, die Case IQ beim Anlegen eines Engagements übernimmt:
- Plattformerkennung: Auf welche konkrete Plattform bezieht sich die Anfrage?
- Produktidentifikation: Welcher konkrete Cloud-Service ist betroffen?
- Schweregrad-Einschätzung: Wie dringend ist das Problem?
- Asset-Identifikation: Welches Projekt oder Konto ist betroffen?
- Extraktion technischer Details: Welche konkreten Informationen brauchen unsere Engineers?
Über zwei Wochen hinweg haben wir 21.517 Traces aus 755 echten Kunden-Engagements verarbeitet und dabei Latenz, Kosten und Genauigkeit gemessen.
Den Vergleich hat uns unsere bestehende LangChain-Integration deutlich erleichtert. Da wir LangChain bereits für unsere GPT-4o-Implementierung nutzten, war das Einbinden der Vergleichsmodelle unkompliziert: Wir haben ChatGroq-Aufrufe parallel zu unserer bestehenden ChatOpenAI-Integration eingebaut und asynchron ausgeführt, um das Produktionssystem nicht zu beeinträchtigen.
Für die umfassende Instrumentierung haben wir LangSmith eingesetzt – darüber wurden Latenzwerte, Token-Verbrauch, Fehlerraten sowie Input- und Output-Logs über alle Traces hinweg automatisch erfasst.
**Die Ergebnisse: deutlich mehr Tempo bei kleinen Qualitätseinbußen**
Die Ergebnisse haben unsere Erwartungen übertroffen:
⚡ 4–5x schneller
- Plattformerkennung: 571 ms → 249 ms (2,3x schneller, mit Llama 3.3 70B)
- Produkterkennung: 851 ms → 406 ms (2,1x schneller, mit Llama 3.1 8B)
- Schweregrad-Erkennung: 605 ms → 234 ms (2,6x schneller, mit Llama 3.3 70B)
- Asset-Erkennung: 593 ms → 220 ms (2,7x schneller, mit Llama 3.3 70B)
- Extraktion technischer Details: 1.914 ms → 334 ms (5,7x schneller, mit Llama 3.1 8B)
💰 Bis zu 50x niedrigere Kosten
Tempo war unser Hauptziel – aber die Kostenersparnis war beachtlich: Manche Aufgaben ließen sich bei gleichbleibender Qualität 50x günstiger ausführen.
🎯 Performance bleibt stabil
In manuellen Reviews echter Kunden-Engagements zeigte sich: Während GPT-4o auf 92–96 % Genauigkeit kam, lieferten unsere schnelleren Alternativen ebenfalls solide Ergebnisse:
- Llama 3.3 70B: 88–96 % Genauigkeit bei 2–3x höherem Tempo
- Llama 3.1 8B: 55–88 % Genauigkeit bei 4–5x höherem Tempo
**Die Gewinnerstrategie: ein hybrider Ansatz**
Statt uns auf ein einzelnes "bestes" Modell festzulegen, sind wir zu dem Schluss gekommen, dass für eine insgesamt optimale Lösung verschiedene Modelle nötig sind:
- Llama 3.1 8B für Produkterkennung und Extraktion technischer Details (diese Aufgaben hängen voneinander ab – hier zählt Tempo am meisten)
- Llama 3.3 70B für Plattform- und Schweregrad-Erkennung sowie Asset-Identifikation (Llama 3.1 8B hatte mit dieser Aufgabe sichtbar Schwierigkeiten – wobei wir glauben, dass sich das durch gezieltes Prompting noch verbessern lässt)
Das Ergebnis? Die Gesamtantwortzeit sinkt von über 3 Sekunden auf unter 1 Sekunde – ein Tempogewinn von 3–4x insgesamt. Mit diesem hybriden Ansatz rechnen wir zudem mit einer Kostenersparnis von rund 93 % auf unsere Gesamtrechnung.
**Was das für Sie bedeutet**
⚡ Nahezu sofortige Antworten: Wenn Sie Ihr Cloud-Infrastruktur-Problem schildern, analysiert CaseIQ es jetzt fast in Echtzeit und fragt die richtigen technischen Details ab.
🔄 Echtzeit-Supportkanäle: Diese Tempogewinne eröffnen neue Möglichkeiten. Wir prüfen gerade, Support direkt in Slack oder anderen Messaging-Plattformen anzubieten, auf denen unsere Kunden ohnehin unterwegs sind.
🚀 Bessere Lösung beim ersten Kontakt: Genauere und vollständigere Problembeschreibungen für unsere Spezialisten bedeuten kürzere Reaktionszeiten und weniger Hin und Her.
**Erkenntnisse und Ausblick**
Die vollständigen technischen Details sind spannend (und hier verfügbar) – die wichtigsten Erkenntnisse lassen sich aber auf zwei Punkte bringen:
- Strategische Modellauswahl zahlt sich aus: Eine sorgfältige Auswahl von Anbieter und Modell, kombiniert mit klugen Architekturentscheidungen, kann dramatische Latenzverbesserungen bringen (von über 3 Sekunden auf unter 1 Sekunde) – mit massiven Kosteneinsparungen als willkommenem Bonus.
- Menschliche Bewertung ist unersetzlich: Automatisierte Metriken liefern nützliche Anhaltspunkte, aber sobald Text und Menschen ins Spiel kommen, bleibt die manuelle Prüfung essenziell, um die tatsächliche Performance einzuschätzen. Es gibt immer Nuancen, die nur Menschen sauber bewerten können.
Bei DoiT leben wir das Prinzip "powered by technology, perfected by people". Diese Verbesserungen sorgen dafür, dass unsere KI die Vorarbeit bereits geleistet hat, wenn Sie die menschliche Expertise unserer CREs brauchen – damit Sie schnellstmöglich Antworten erhalten.
—
Möchten Sie das verbesserte Case IQ selbst erleben? Sprechen Sie noch heute mit uns und erfahren Sie, wie wir Sie unterstützen können.