Quando o problema é crítico na infraestrutura em nuvem, cada segundo conta. Você precisa de ajuda rápida — e que seja precisa. Mas, mesmo sem pressa, ninguém quer perder um tempo precioso preenchendo formulários enormes; você quer descrever o problema e deixar o resto com a gente.

Reduzir latência e custo de uma vez só? Tô dentro!
**O desafio: deixar o suporte com IA mais ágil e interativo**
Na DoiT, você conta com a Ava para tirar dúvidas de FinOps e nuvem. Mas, em alguns momentos, bate aquela vontade de conversar com um especialista humano. É aí que entra o nosso sistema Case IQ, que ajuda os clientes a informar os detalhes técnicos certos na hora de abrir um chamado, garantindo que nossos Customer Reliability Engineers (CREs) tenham tudo o que precisam para resolver os problemas rapidamente.
A ideia nasceu no nosso hackathon do verão de 2024 e foi construída sobre as APIs da OpenAI. Mas resolvemos ir além do status quo e melhorar ainda mais, com foco na latência das recomendações ao cliente para deixar o sistema mais ágil e interativo.
**O experimento: testando cinco modelos em latência, custo e desempenho**
Para resolver isso, montamos um experimento abrangente de 2 semanas comparando nosso modelo atual (GPT-4o, da OpenAI) com quatro alternativas:
- GPT-4.1 mini (modelo mais novo e rápido da OpenAI)
- Llama 3.1 8B (modelo menor e ultrarrápido, no hardware especializado da Groq)
- Llama 3.3 70B (modelo maior e mais capaz, na Groq)
- Llama 4 Scout 17B (modelo em preview da nova família da Meta, com capacidades promissoras)
O objetivo principal era encontrar um modelo com latências menores que a do GPT-4o (nossa baseline). Já contávamos com um (pequeno) impacto na qualidade das respostas e tratávamos qualquer redução de custo como um bônus.
Testamos esses modelos em cinco tarefas que o Case IQ executa quando você cria um engajamento:
- Detecção de plataforma: a qual plataforma específica a solicitação se refere
- Identificação de produto: qual serviço de nuvem precisa de ajuda?
- Avaliação de severidade: qual a urgência do problema?
- Identificação de ativo: qual projeto ou conta foi afetado?
- Extração de detalhes técnicos: de quais informações específicas nossos engenheiros precisam?
Em duas semanas, processamos 21.517 traces em 755 engajamentos reais de clientes, medindo latência, custo e acurácia.
A base técnica que facilitou essa comparação foi nossa integração já existente com o LangChain. Como já usávamos LangChain na implementação com GPT-4o, adicionar os modelos de comparação foi simples: incluímos chamadas ao ChatGroq ao lado da nossa integração com o ChatOpenAI, executando-as de forma assíncrona para não impactar o ambiente de produção.
Usamos o LangSmith para uma instrumentação completa, capturando automaticamente medições de latência, uso de tokens, taxas de erro e logs de entrada/saída em todos os traces.
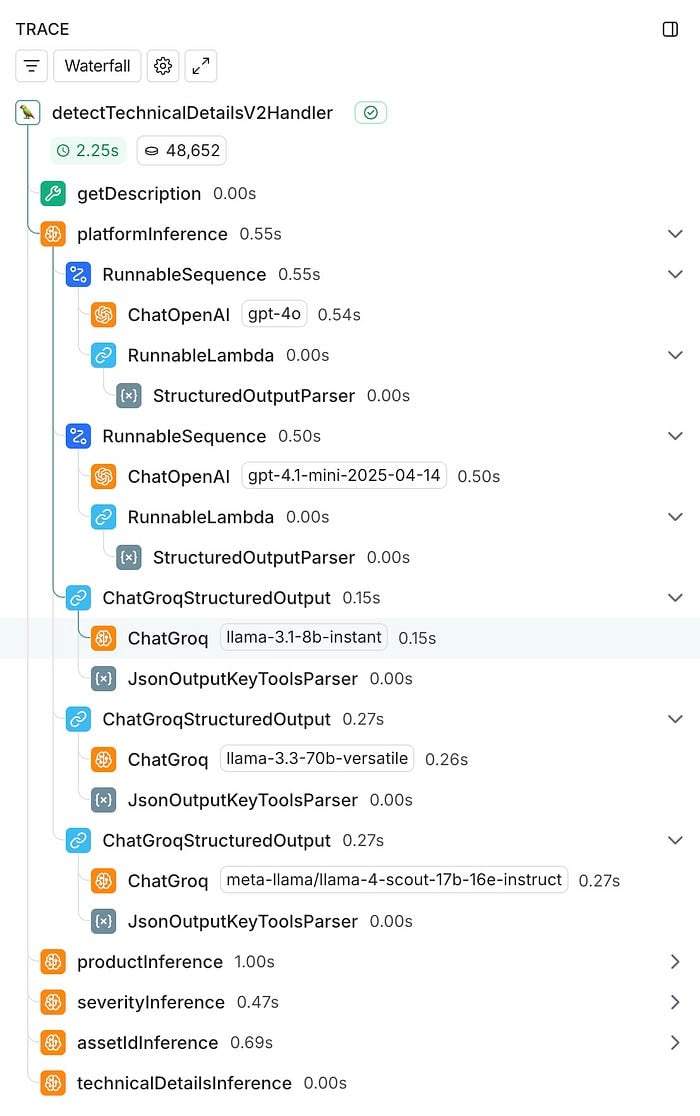
**Os resultados: mais velocidade com um pequeno sacrifício na qualidade**
Os resultados superaram nossas expectativas:
⚡ Ganhos de velocidade de 4x a 5x
- Detecção de plataforma: 571ms → 249ms (2,3x mais rápido, com Llama 3.3 70B)
- Detecção de produto: 851ms → 406ms (2,1x mais rápido, com Llama 3.1 8B)
- Detecção de severidade: 605ms → 234ms (2,6x mais rápido, com Llama 3.3 70B)
- Detecção de ativo: 593ms → 220ms (2,7x mais rápido, com Llama 3.3 70B)
- Extração de detalhes técnicos: 1.914ms → 334ms (5,7x mais rápido, com Llama 3.1 8B)
💰 Redução de custos de até 50x
A velocidade era o foco, mas a economia surpreendeu — algumas tarefas ficaram 50x mais baratas sem perder qualidade.
🎯 Mantendo o desempenho
Numa revisão manual de engajamentos reais, vimos que o GPT-4o cravou 92–96% de acurácia, e nossas alternativas mais rápidas se saíram muito bem:
- Llama 3.3 70B: 88–96% de acurácia, com ganhos de velocidade de 2x a 3x
- Llama 3.1 8B: 55–88% de acurácia, com ganhos de velocidade de 4x a 5x
**A estratégia vencedora: uma abordagem híbrida**
Em vez de escolher um único "melhor" modelo, concluímos que precisaríamos de modelos diferentes para chegar à solução ideal:
- Llama 3.1 8B para detecção de produto e detalhes técnicos (como essas tarefas têm dependências entre si, é onde a velocidade pesa mais)
- Llama 3.3 70B para detecção de plataforma, severidade e identificação de ativo (o Llama 3.1 8B pareceu ter dificuldade nessas tarefas, embora acreditemos que dá para otimizar via prompting)
O resultado? O tempo total de resposta caiu de mais de 3 segundos para menos de 1 segundo: um ganho geral de 3x a 4x em velocidade. E mais: com essa abordagem híbrida, esperamos uma economia de aproximadamente 93% na conta total.
**O que isso significa para você**
⚡ Respostas quase instantâneas: quando você descreve seu problema de infraestrutura em nuvem, o Case IQ já analisa e solicita os detalhes técnicos certos praticamente na hora.
🔄 Canais de suporte em tempo real: esses ganhos de velocidade abrem novas possibilidades. Estamos avaliando levar o suporte direto para o Slack ou outras plataformas de mensagens onde nossos clientes já estão.
🚀 Melhor resolução já no primeiro contato: descrições mais precisas e completas para os nossos especialistas significam tempos de resposta menores e menos idas e vindas.
**Conclusões e próximos passos**
Os detalhes técnicos completos são fascinantes (e estão disponíveis aqui), mas o aprendizado principal foi duplo:
- A seleção estratégica de modelos funciona: a escolha cuidadosa de provedor e modelo, combinada com boas decisões arquiteturais, gera melhorias drásticas de latência (de mais de 3 segundos para menos de 1) e, de quebra, reduções massivas de custo.
- A avaliação humana é insubstituível: métricas automatizadas dão boas baselines, mas a revisão manual continua essencial para entender o desempenho real quando o assunto envolve texto e pessoas; sempre há nuances que só humanos conseguem avaliar de verdade.
Na DoiT, acreditamos em ser "powered by technology, perfected by people". Essas melhorias garantem que, quando você precisar da expertise humana dos nossos CREs, nossa IA já terá feito o trabalho de base para entregar respostas no menor tempo possível.
—
Quer experimentar o Case IQ aprimorado na prática? Fale com a gente hoje mesmo e veja como podemos ajudar.