So bleiben Ihre Dashboards erhalten – auch wenn Sie Grafana neu deployen oder in eine andere Umgebung bzw. einen anderen Cluster wechseln.

So bleiben Ihre Dashboards erhalten – auch beim Neu-Deployment von Grafana oder beim Wechsel in eine andere Umgebung bzw. einen anderen Cluster
Prometheus hat sich als De-facto-Monitoring-Tool etabliert und bildet zusammen mit Grafana und Alertmanager in vielen Unternehmen den kompletten Observability- und Alerting-Stack.
Diese Komponenten einzeln zu verwalten und auszurollen ist allerdings mühsam – und birgt das Risiko, dass sie bei Infrastrukturänderungen aus dem Takt geraten. Mit dem von der prometheus-community gepflegten kube-prometheus-stack Helm Chart lässt sich die Konfiguration aller drei Tools sauber an einer Stelle bündeln – in einer einzigen Helm-values-Datei. In diesem Blogpost zeigen wir, wie wir Grafana-Dashboards im Helm Chart ergänzen, sodass sie auch beim Neu-Deployment von Grafana oder beim Wechsel in eine andere Umgebung bzw. einen anderen Cluster erhalten bleiben.
Voraussetzungen
Zunächst müssen wir das Repository mit dem kube-prometheus-stack Helm Chart klonen. Wenn wir das Chart remote ziehen und anwenden, lassen sich eigene Dashboards nämlich nicht im Code ablegen – das geht nur, wenn wir das Chart aus einer lokalen Kopie heraus deployen. Außerdem brauchen wir folgende Tools auf der Workstation:
- Git
- Helm
- Kubectl
- IDE Ihrer Wahl
$ git clone https://github.com/prometheus-community/helm-charts.git$ cd helm-charts/charts/kube-prometheus-stackIm Charts-Ordner angekommen, wechseln wir in den Grafana-Dashboards-Ordner – dort liegen alle mitgelieferten Standard-Dashboards.
$ cd templates/grafana/dashboards-1.14/$ lsalertmanager-overview.yaml grafana-overview.yamlk8s-resources-pod.yaml namespace-by-workload.yamlpod-total.yaml statefulset.yamlapiserver.yaml k8s-coredns.yamlk8s-resources-workload.yaml node-cluster-rsrc-use.yamlWie man sieht, bringt die Grafana-Installation eine ganze Reihe Dashboards mit. Sie werden aus diesem Verzeichnis heraus angewendet, indem die enthaltenen ConfigMap-Templates ausgerollt werden.
Eigenes Dashboard exportieren
Sobald wir in Grafana ein eigenes Dashboard erstellt und gespeichert haben, brauchen wir einen JSON-Export, den wir im nächsten Schritt in unsere ConfigMap übernehmen. Klicken Sie dazu auf das Einstellungs-Zahnrad Ihres Dashboards und wählen Sie links den Eintrag "JSON Model". Hier können wir das JSON kopieren und für später sichern:
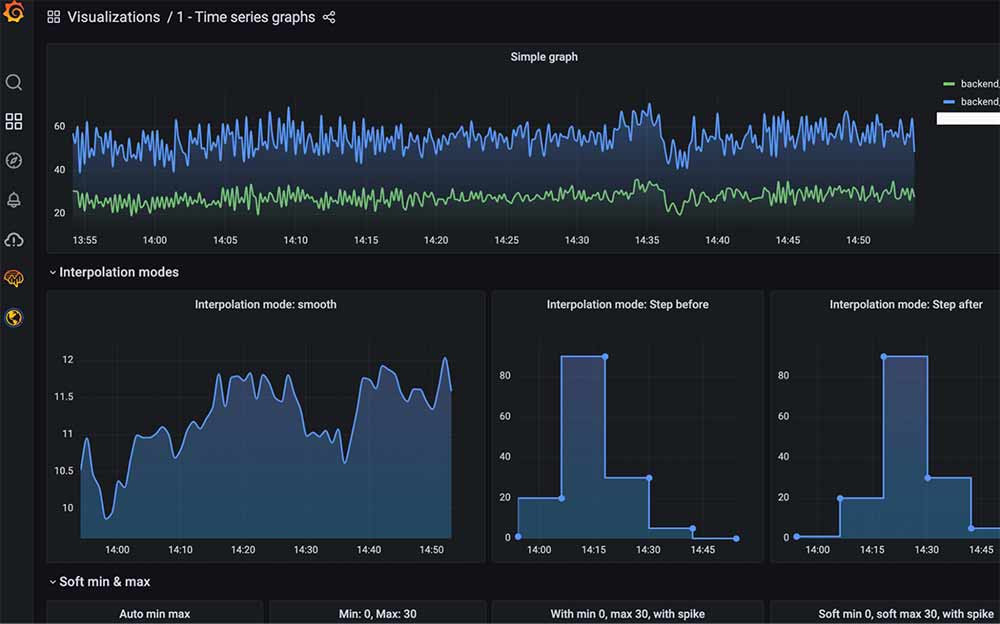
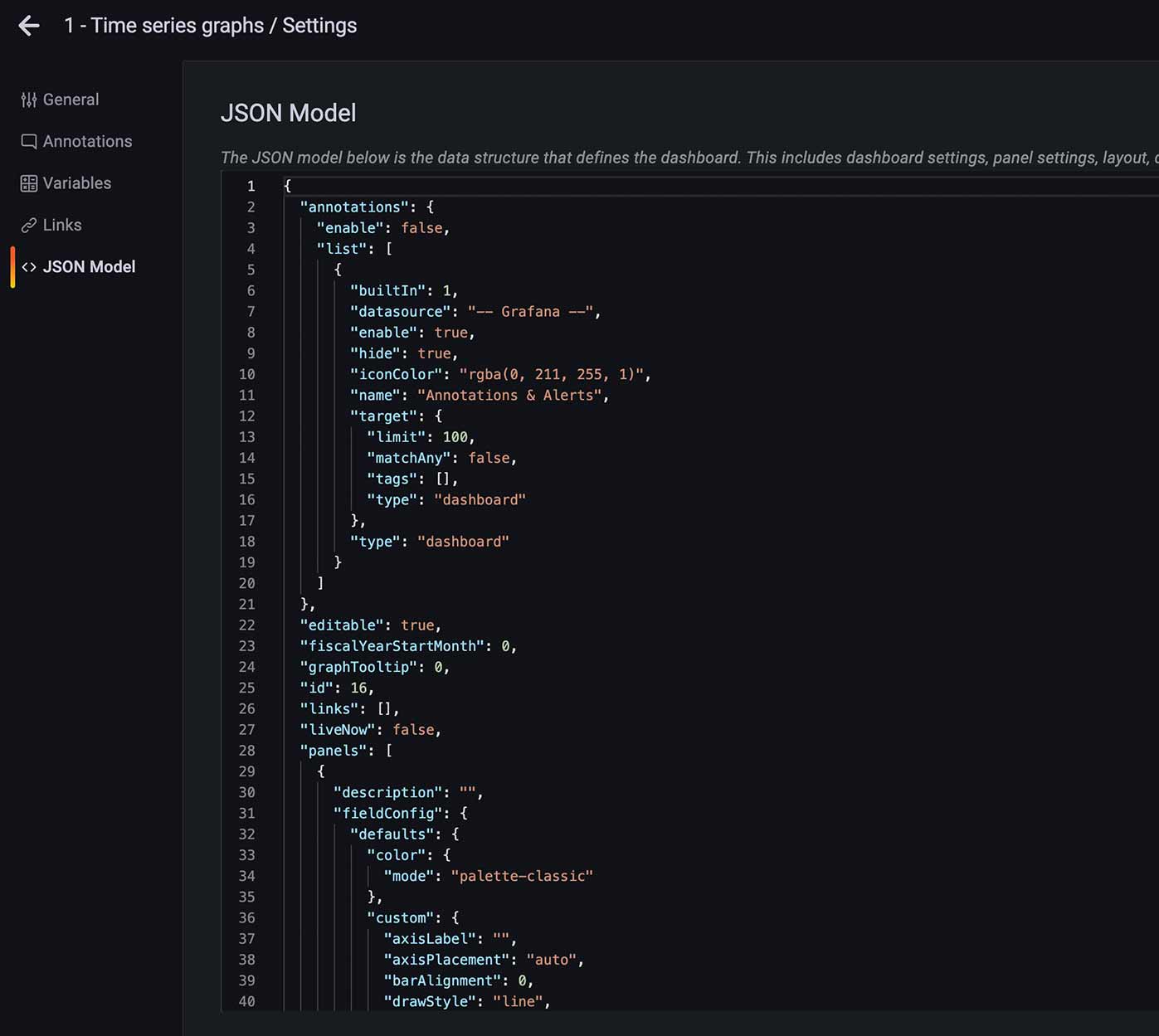
Eigenes Dashboard hinzufügen
Nun können wir unser eigenes ConfigMap-Helm-Template in den Dashboards-Ordner einfügen. Am einfachsten ist es, eine der vorhandenen YAML-Dateien in diesem Ordner zu duplizieren, sie nach Ihrem Dashboard zu benennen und das JSON dort einzufügen. In meinem Beispiel heißt sie – passend zum oben erstellten Dashboard – "time-series-graph.yaml". Jetzt geht es an die Anpassung des Templates. Zuerst entfernen wir den Kommentar am Anfang der Datei – konkret diesen Teil:
{{- /*Generated from 'alertmanager-overview' from https://raw.githubusercontent.com/prometheus-operator/kube-prometheus/main/manifests/grafana-dashboardDefinitions.yamlDo not change in-place! In order to change this file first read following link:https://github.com/prometheus-community/Helm-charts/tree/main/charts/kube-prometheus-stack/hack*/ -}}Anschließend passen wir den Namen unserer ConfigMap an mehreren Stellen an – zuerst hier:
apiVersion: v1kind: ConfigMapmetadata: namespace: {{ template "kube-prometheus-stack-grafana.namespace" . }} name: {{ printf "%s-%s" (include "kube-prometheus-stack.fullname" $) "alertmanager-overview" | trunc 63 | trimSuffix "-" }}Ich ersetze "alertmanager-overview" – die Vorlage, von der wir das Template ursprünglich kopiert haben – durch "time-series-graphs", passend zu meinem Dashboard- und YAML-Dateinamen:
apiVersion: v1kind: ConfigMapmetadata: namespace: {{ template "kube-prometheus-stack-grafana.namespace" . }} name: {{ printf "%s-%s" (include "kube-prometheus-stack.fullname" $) "time-series-graph" | trunc 63 | trimSuffix "-" }}Als Nächstes ändern wir den Namen im data-Abschnitt des ConfigMap-Templates wie folgt:
data: alertmanager-overview.json: |-zu
data: time-series-graph.json: |-Anschließend ersetzen wir das JSON des bestehenden Dashboards direkt unter dieser Zeile durch das JSON, das wir aus den Grafana-Dashboard-Einstellungen kopiert haben – siehe unten. Achten Sie darauf, das gesamte JSON um mindestens einen Tabulator einzurücken:
data:
time-series-graphs.json: |-
{
"__inputs": [\
\
],
"__requires": [\
\
],
"annotations": {
"list": [\
\
]
},
"editable": false,
"gnetId": null,
"graphTooltip": 1,
"hideControls": false,
"id": null,
"links": [\
\
],
"refresh": "30s",
"rows": [\
...\
```\
\
Helm-Templates rendern\
Nachdem die YAML-Datei für das Dashboard-ConfigMap-Helm-Template angelegt ist, prüfen wir, welche YAML-Manifeste das Helm Chart erzeugt – um sicherzugehen, dass die ConfigMap für unser Dashboard korrekt generiert wird:
\
# Repos für die benötigten Charts in Helm hinterlegen\
$ Helm repo add grafana https://grafana.github.io/Helm-charts\
\
$ Helm repo add prometheus-community https://prometheus-community.github.io/Helm-charts\
\
# Alle Chart-Abhängigkeiten ziehen und aktualisieren\
$ Helm dependency build\
\
$ Helm repo update\
```\
\
Nun können wir mit dem Befehl "Helm template" die YAML-Manifeste aus unseren Helm-Templates rendern und in eine Datei schreiben, um sie später zu prüfen. Mit dem Flag —validate stellen wir sicher, dass es sich um gültige YAML-Kubernetes-Manifeste im aktuellen Kontext des Kubernetes-Clusters handelt:\
\
```\
$ Helm template kube-prometheus-stack . --validate > rendered-template.yaml\
```\
\
Anschließend werfen wir einen Blick in die Datei rendered-template.yaml, um zu prüfen, dass unsere ConfigMap angelegt wurde und im nächsten Schritt – beim Helm-install-Befehl – auch wirklich angewendet wird:\
\
```\
$ cat rendered-template.yaml\
…\
---\
# Source: kube-prometheus-stack/templates/grafana/dashboards-1.14/time-series-graphs.yaml\
apiVersion: v1\
kind: ConfigMap\
metadata:\
namespace: default\
name: kube-prometheus-stack-time-series-graphs\
annotations:\
{}\
labels:\
grafana_dashboard: "1"\
app: kube-prometheus-stack-grafana\
app.kubernetes.io/managed-by: Helm\
app.kubernetes.io/instance: kube-prometheus-stack\
app.kubernetes.io/version: "32.2.1"\
app.kubernetes.io/part-of: kube-prometheus-stack\
chart: kube-prometheus-stack-32.2.1\
release: "kube-prometheus-stack"\
heritage: "Helm"\
data:\
time-series-graphs.json: |-\
{\
"annotations": {\
"enable": false,\
"list": [\
{\
"builtIn": 1,\
"datasource": "-- Grafana --",\
"enable": true,\
"hide": true,\
"iconColor": "rgba(0, 211, 255, 1)",\
"name": "Annotations & Alerts",\
```\
\
Eine kurze Suche nach "time-series" in der Datei bestätigt: Unsere ConfigMap wurde angelegt und der data-Abschnitt enthält das JSON des zuvor hinzugefügten Dashboards.\
\
Zum Schluss rollen wir das Helm Chart auf unseren Kubernetes-Cluster aus. Sobald Grafana läuft, können wir prüfen, ob das Dashboard vorhanden ist:\
\
```\
$ Helm install kube-prometheus-stack .\
```\
\
\
\
Verwandte Blogposts\
![]()
\
Amazon Bedrock Pricing: Der CloudOps-Leitfaden für KI-Kosten im Griff\
Amazon Bedrock rechnet pro verarbeitetem Input- und Output-Token ab – die Kosten variieren je nach Modell, Preismodell und Workload

\
Databricks Pricing erklärt: DBUs, Tiers und Kostenkontrolle\
Databricks rechnet Compute in Databricks Units (DBUs) sekundengenau ab – zusätzlich zu einer separaten Rechnung Ihres

\
Was sind Cloud-Infrastructure-Services? Ein CloudOps-Leitfaden\
Cloud-Infrastructure-Services – also Compute, Storage und Networking – bilden die operative Basis, die jedes CloudOps-Team verwaltet. Die richtige Auswahl
Suche
Suche
\
Termin mit unserem Team vereinbaren\
Region wählenAmericasEMEAAPACIm nächsten Schritt erhalten Sie verfügbare Termine zur Auswahl