Wenn Sie hier gelandet sind, haben Sie vermutlich bereits Teil 1 (Das Warum) gelesen und möchten nun wissen, wie sich cloud-native Developer-Umgebungen sauber aufsetzen lassen. Sehr gut!
Schauen wir uns am Beispiel eines bestehenden Projektteams an, wie sich dessen Entwicklungs-Workflow verbessern lässt.
Dieser Leitfaden ist mit Blick auf GCP (Google Cloud Platform) entstanden, die Konzepte lassen sich aber genauso auf AWS übertragen.

Foto von Jason Richard auf Unsplash
📖 Fallstudie
Ein Unternehmen namens MajesticFantastic bietet einige Produkte rund um den Zahlungsverkehr an 💸
Das Billing-Projektteam verantwortet die Entwicklung einer Abrechnungsanwendung.
Diese setzt sich wie folgt zusammen:
- Mehrere Microservices, die als Container in GKE laufen 🛳
- Genutzte GCP-Cloud-Services: Pub/Sub, Cloud SQL (PostgreSQL), Cloud Monitoring, Container Registry.
- Aktuelle Umgebungen: Dev, Prod.
- Ein Team aus zwei Entwicklern: David und Martha. Schon bald stößt ein Entwickler namens Ezekiel dazu, gefolgt von weiteren Engineers — das Unternehmen wächst rasant. Spannende Zeiten! 🚀
Proof of Concept
Wir führen einen neuen Umgebungstyp ein und nennen ihn "Personal Environment".
Unser POC für die Personal Environment besteht aus:
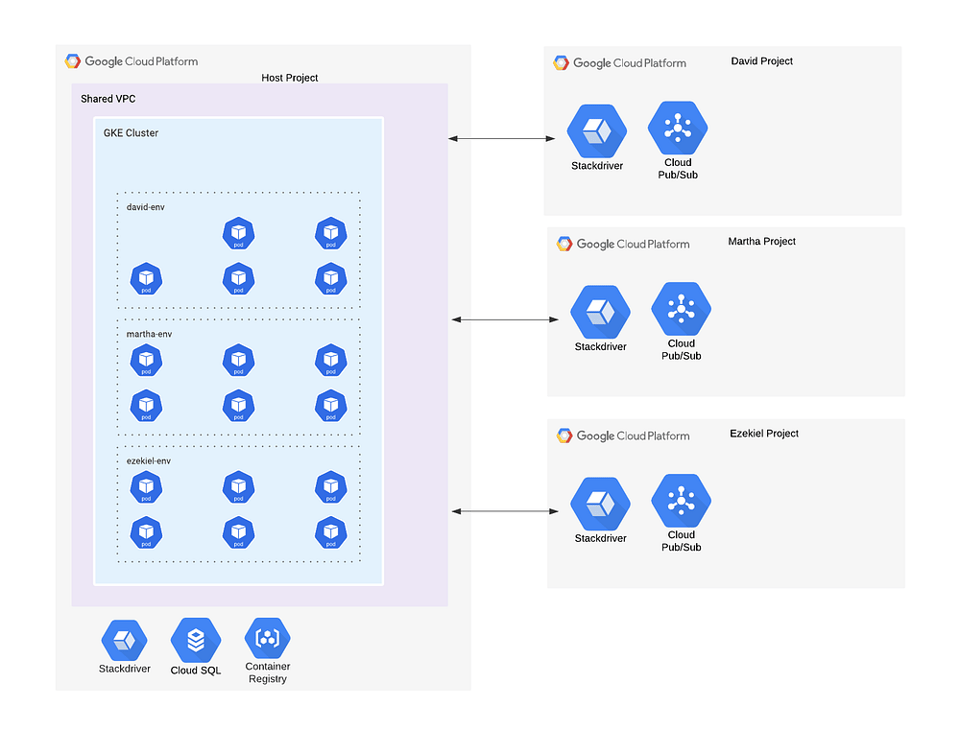
- Einem GCP-Projekt, das als Host-Projekt dient. Dort liegen der GKE-Cluster, die Cloud-SQL-Instanz und die Container-Images in GCR.
- Mehreren persönlichen GCP-Projekten — eines pro Entwickler. Jedes Projekt enthält die nicht geteilten Ressourcen, die dem jeweiligen Entwickler zugeordnet sind. In unserem Beispiel sind das die Pub/Sub-Topics und -Subscriptions.
- Einer Shared VPC. Deren Host ist das Host-Projekt, und jedes persönliche Projekt fungiert als Shared-VPC-Service-Projekt.
Multi-Tenant-GKE-Cluster
Pro Umgebung vergeben wir einen K8s-Namespace (Davids Umgebung erhält beispielsweise den Namespace david-env, Martha bekommt martha-env und so weiter).
Jede Umgebung greift ausschließlich auf den eigenen Namespace zu und nutzt keine Ressourcen aus den Namespaces anderer Umgebungen.
Hinweis: Sicherheitsmaßnahmen erzwingen wir vorerst nicht. Sie lassen sich später ergänzen — mehr dazu am Ende des Artikels.
Multi-Tenant-Cloud-SQL
Cloud SQL unterstützt Users und Databases, sodass wir pro Umgebung jeweils einen User und eine Database anlegen können (Hinweis: Wir nutzen eine einzige Cloud-SQL-Instanz und zahlen entsprechend nur für diese eine!).
Wir legen eine einzelne private Cloud-SQL-Instanz an und "verbinden" sie über Private Service Access mit unserer Shared VPC.
Jetzt wird es praktisch! 👩🔧
Das Repository developer-envs enthält den gesamten relevanten IaC- und GitOps-Code.
Infrastructure-as-Code (IaC)
Manuell erledigen müssen Sie das nicht. Wir nutzen Terraform als Infrastructure-as-Code, das alles für uns aufzusetzen. Zum Code!
Mit dem Terraform Kubernetes Provider richten wir pro Umgebung einen K8s-Namespace ein und erstellen allgemeine ConfigMaps mit infrastrukturbezogenen Parametern (z. B. PubSub-Topic-Name, GCP-Projekt-ID usw.).
Ich habe in der gesamten Lösung Googles Terraform-Module aus dem Cloud Foundation Toolkit verwendet und fand sie sehr angenehm in der Handhabung. Sie bringen außerdem einige Best Practices von Google mit — also unbedingt mal reinschauen.
Ein IaC-Tool wie Terraform einzusetzen, ist für dieses Konzept essenziell: Es geht ja gerade darum, fehleranfällige manuelle Arbeit zu reduzieren und zu automatisieren sowie alle Konfigurationen beim Skalieren konsistent zu halten. Ein bisschen Mehraufwand jetzt — und deutlich weniger Arbeit später.
GitOps
Anschließend nutzen wir ArgoCD, um unsere verschiedenen Umgebungen in K8s zu steuern und auszurollen. ArgoCD ist ein beliebtes GitOps-Tool für Continuous Delivery und passt aus meiner Sicht hervorragend zu unserem Multi-Tenant-Szenario. Zum Code!
Den Großteil unserer K8s-Ressourcen definieren wir als YAML-Dateien und passen die Konfiguration mit Kustomize an.
Kustomize ist ein Konfigurationstool, mit dem Sie eine "Base"-Konfiguration definieren und darüber zahlreiche "Overlays" legen, die alle dieselbe Basis teilen (eine Art Vererbung für Arme). Ideal also, wenn Sie mehrere Umgebungen mit gemeinsamem Konfigurations-Vorfahren haben.
Erfreulicherweise unterstützt unsere CD-Lösung ArgoCD Kustomize von Haus aus.
Ich finde Kustomize einfach und unkompliziert. Selbstverständlich können Sie aber auch ein anderes Tool wie Helm verwenden.
Beispielhafte Microservices
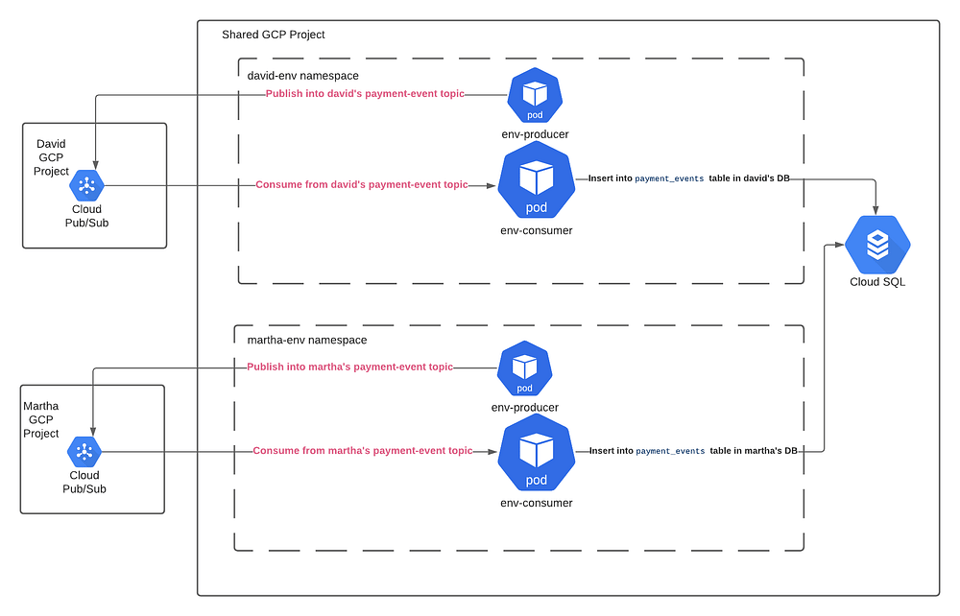
Wir deployen zwei recht einfache, in Go geschriebene Microservices.
Der Microservice env-producer publiziert alle 10 Sekunden Payment-Events über ein Pub/Sub-Topic.
Der Microservice env-consumer konsumiert die "Payment Event"-Nachrichten aus Pub/Sub und schreibt sie in eine PostgreSQL-Tabelle.
Das Entscheidende an diesen Services: Unser Multi-Environment-Setup ist für sie transparent, denn die Umgebungsdetails reichen wir als Environment Variables hinein. Konfiguration und Code zu trennen ist eine zentrale Twelve-Factor-Praxis, die man kennen sollte.
Im Kern laufen diese Microservices auf jeder Umgebung separat und greifen ausschließlich auf die umgebungsspezifischen Ressourcen zu.
Loslegen 🏃🏻♂️
Klonen Sie das Beispiel-Repo und folgen Sie den Anweisungen in der README.md.
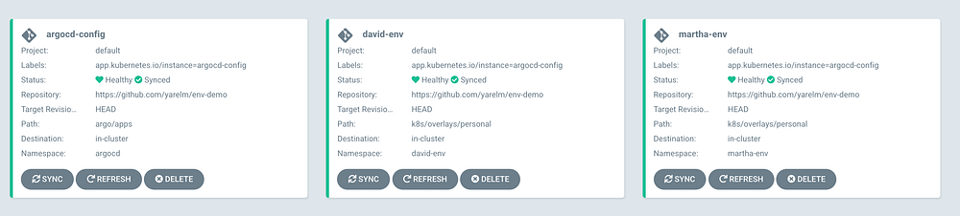
Anschließend sollte die ArgoCD-Konsole etwa so aussehen.
Sie ist die zentrale Stelle, an der Sie all Ihre Umgebungen auf einem einzigen Dashboard im Blick behalten. Naheliegenderweise möchten Sie hier auch Ihre weiteren Umgebungen (z. B. Dev und Prod) ergänzen, eventuell in einem separaten ArgoCD-"Project".
Beachten Sie die Anwendung argocd-config, die für das Self-Syncing der ArgoCD-Konfigurations- und Installationsdateien zuständig ist, sowie zwei weitere Anwendungen — eine pro Entwickler.
So deployen Sie Änderungen in Ihre Umgebung
Sie haben einen Service angepasst und möchten die Änderung in Ihre Umgebung ausrollen. Welche Optionen haben Sie?
Option 1: Eigenes Image bauen
Sie passen den Quellcode an und bauen anschließend ein neues Container-Image. Eine kurze Anpassung des Image-Tags in seiner Anwendung in ArgoCD reicht, um das neue Image zügig zu deployen.
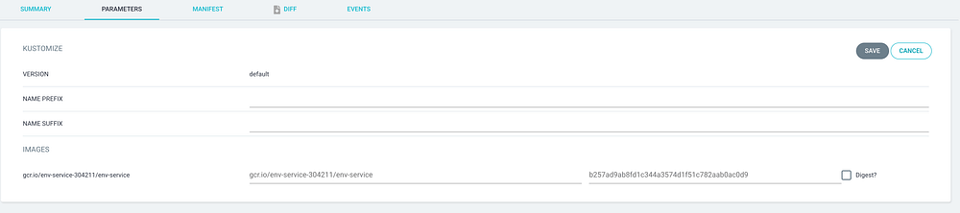
Anwendungsinfos in ArgoCD, in denen ein Entwickler den Image-Tag ändern und auf "Save" klicken kann.
Das geht manuell oder automatisiert über eine CI-Pipeline bzw. eigene Skripte. (ArgoCD bringt zudem eine CLI mit, mit der sich das automatisieren lässt.)
Option 2: Lokal ausführen
Moment … was? Widerspricht das nicht genau dem, was wir eigentlich erreichen wollen?
Hier kommt Telepresence ins Spiel. Telepresence ist eines der coolsten Tools, das mir in letzter Zeit untergekommen ist. Ich habe es schon oft eingesetzt und es hat meine Produktivität als Entwickler spürbar gesteigert.
In einem Satz lässt sich kaum erklären, was es tut, aber ich versuche es. Hier eine Beschreibung von der Website:
Telepresence ersetzt Ihren normalen Pod im Kubernetes-Cluster durch einen bidirektionalen Netzwerk-Proxy. Dieser Pod leitet Daten aus Ihrer Kubernetes-Umgebung (z. B. TCP-Verbindungen, Environment Variables, Volumes) an den lokalen Prozess weiter. Das Networking des lokalen Prozesses wird transparent so überschrieben, dass DNS-Abfragen und TCP-Verbindungen über den Proxy in den Remote-Kubernetes-Cluster geroutet werden.
Oder einfacher gesagt: Sie führen Ihren Service lokal auf Ihrem Rechner aus, während eingehende und ausgehende Verbindungen, Environment Variables und Volumes zum K8s-Cluster gespiegelt werden. Praktisch! 👍
Angenommen, Sie haben den Microservice env-consumer angepasst und wollen die Änderung testen. Dann führen Sie aus:
Innerhalb weniger Sekunden ist die Änderung deployt und läuft.
Im Kern ersetzt Telepresence den Pod Ihres Service durch einen Proxy-Pod, während Ihr Service lokal läuft und mit dem Proxy-Pod kommuniziert.
Das Schöne daran: Sie führen eine lokale App aus, sind dabei aber tatsächlich remote sowohl mit PubSub als auch mit Cloud SQL (PostgreSQL) verbunden!
Und das alles, ohne den Anwendungscode anzufassen oder Zertifikate und Secret Keys einzurichten. Derselbe Code in der Personal Environment wie in Production!
Bin ich fertig, drücke ich Strg+C — und das Image wird auf den vorherigen Stand zurückgesetzt. Wunderbar! 🤩

Eine Demo unseres Beispiel-Service mit Telepresence
Stellen Sie sich vor, Sie fixen einen Bug, starten Telepresence, warten ein paar Sekunden — und merken, dass Sie den Service zum Absturz gebracht haben. Tja, also nochmal nachbessern. Die Feedback-Schleife ist hier richtig schnell! 😁
Beachten Sie: Ich habe hier kein Docker-Image gebaut. Ich kompiliere den geänderten Quellcode und führe das Executable lokal aus. Sie können Telepresence aber auch so konfigurieren, dass es das Docker-Image baut und ersetzt.
Personal Environments und Onboarding
Ezekiel ist gerade als Entwickler ins Team gekommen! Willkommen! Er hat seinen Laptop und etwas Swag bekommen. Yay! 🥳
Im Rahmen seines Onboardings sollen Sie eine Personal Environment für Ezekiel einrichten, damit er mit der Anwendung und der Infrastruktur experimentieren und kleine Änderungen ausprobieren kann, um deren Auswirkungen zu sehen.
So gehen Sie dabei vor:
- Bearbeiten Sie die Datei
tf/personal.tfvarsund fügen Sie Ezekiel zur Liste der Tenants hinzu:
2. Wenden Sie die Änderung mit terraform apply -f personal.tfvars an.
3. Fügen Sie eine ArgoCD-Anwendung für Ezekiels Umgebung hinzu, indem Sie das folgende Snippet an argo/apps/applications.yaml anhängen, dann committen und pushen.
Das war's! Da ArgoCD den apps-Ordner synchronisiert, erkennt es automatisch, dass ezekiel-env hinzugekommen ist, und stellt die Umgebung bereit. Ezekiel wird sich freuen.
Personal Environments und Offboarding
Oh nein! David verlässt das Team und stellt sich neuen Herausforderungen!
Schade, wir werden ihn vermissen. ⭐️ 😩
Aber hey — jetzt sehen wir, wie einfach es ist, seine Personal Environment aufzuräumen. 😌
Öffnen Sie argo/apps/applications.yaml, löschen Sie die Anwendungsdefinition david-env und committen und pushen Sie die Änderung. Da ArgoCD den apps-Ordner synchronisiert, erkennt es automatisch, dass david-env entfernt wurde, und löscht die Umgebung.
Anschließend sollten Sie die Infrastruktur der Umgebung entfernen, indem Sie david aus der Tenants-Liste in tf/personal.tfvars löschen und danach terraform apply -f personal.tfvars ausführen.
Fertig! Keine Spur mehr von David 💀
👣 Nächste Schritte
Wenn Sie das auf Ihre Organisation übertragen möchten — gerne. Es gibt aber noch einige zusätzliche Aspekte zu berücksichtigen:
Nur ein POC
Wie bereits erwähnt, handelt es sich um einen POC zu Demonstrations- und Einstiegszwecken. Einige Teile der Implementierung wurden zur Vereinfachung verkürzt. Bitte betrachten Sie die Umsetzung nicht als Best Practice und passen Sie sie an Ihre Anforderungen und Vorlieben an.
Sicherheit
Wie im vorherigen Kapitel angemerkt, kann Sicherheit bei dieser Lösung ein Thema sein. Es gibt mehrere Möglichkeiten, Sicherheit und Isolation darauf aufbauend zu verbessern (z. B. RBAC, Network Policies, Resource Quotas, Pod Anti-Affinity. Mehr Infos finden Sie hier).
Multi-Tenancy
Hier wurden Beispiele für Multi-Tenancy bei Cloud-Services wie GKE, Pub/Sub und Cloud SQL gezeigt — die Konzepte lassen sich aber genauso auf andere Cloud-Services übertragen.
GCP-Projekt pro Entwickler
Der aktuelle Scope des GCP-Projekts pro Entwickler ist bewusst schlank gehalten. Er bildet die Grundlage, auf der Sie diesen Scope erweitern und ausbauen können. So lässt sich beispielsweise ein Routing einrichten, das namespace-spezifische Logs und Metriken in das jeweilige Entwickler-GCP-Projekt sendet. Ein weiteres Beispiel: Im Entwickler-GCP-Projekt lassen sich individuelle Ressourcen außerhalb der Projekt-Mainline starten, um zu testen, ob alles wie geplant funktioniert. Das GCP-Projekt pro Entwickler ist keine Pflicht, sondern eher eine Option — Sie können es bei Bedarf auch weglassen.
Shared VPC
Wir verwenden eine Shared VPC, sodass Ihre verschiedenen persönlichen GCP-Projekte dasselbe VPC-Netzwerk teilen können. Dafür gibt es einige IAM-Voraussetzungen, die Sie beachten sollten. Beispielsweise benötigt der IAM-User Ihres Entwicklers die Rolle compute.networkUser im Host-Projekt, um Ressourcen in der Shared VPC anzulegen.
Alternative Lösungen
Die folgenden Alternativen verfolgen ähnliche Ziele. Einige davon sind kostenpflichtig. Soweit ich das überblicke, bieten diese Alternativen keine "Full-Stack"-Lösung, wenn es darum geht, die Infrastruktur passgenau auf die Deployment-Konfiguration zuzuschneiden, wie es unser POC tut. Sie konzentrieren sich vor allem auf den Kubernetes-Teil. Jede hat je nach Kontext eigene Vor- und Nachteile, die Sie abwägen sollten.
Das war's! Ich hoffe, es hat Ihnen gefallen 🙂
Bei DoiT International arbeiten wir Architects und Engineers stets daran, die Lücke zwischen Infrastruktur und Softwareentwicklung zu schließen — denn wir sind überzeugt, dass beide Seiten dasselbe Ziel verfolgen: Produktivität und Zuverlässigkeit.
Vielen Dank fürs Lesen! Bleiben Sie in Kontakt — folgen Sie uns auf dem DoiT Engineering Blog , dem DoiT LinkedIn-Kanal und dem DoiT Twitter-Kanal . Karrieremöglichkeiten finden Sie unter https://careers.doit-intl.com .