
先日のAWS re:invent 2024で、分析ワークロードに最適化されたフルマネージドApache Icebergテーブルを提供するAmazon S3 Tablesの発表があった。これらのテーブルは、s3tables APIを使用して管理可能なストレージIcebergフォーマットのテーブルを持ち、データ操作のために、Apache SparkやAWSベースの分析サービス (Amazon EMR、Amazon Athena、Amazon Redshift、Amazon EMR、Amazon QuickSight、Amazon Data Firehose)と統合することができる。

スタート
まず最初に、コンソールまたはAWS CLIを使用してテーブルバケットを作成する必要があり、ここで前述のAWSアナリティクスサービスとのテーブルバケット統合を有効にするオプションがあります。
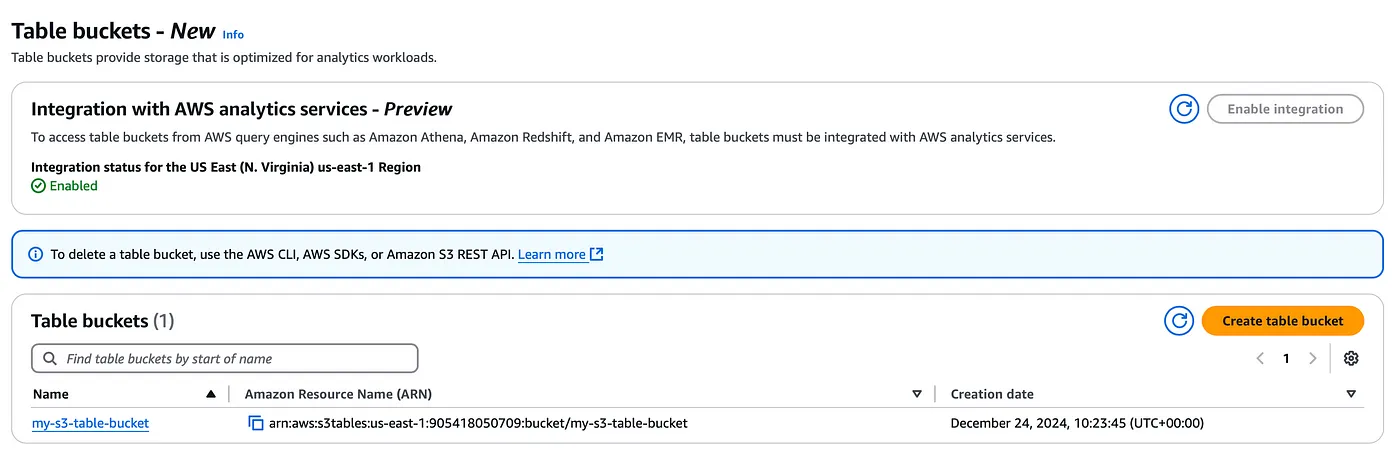
S3 テーブル・バケット・コンソール
テーブルバケットを作成したら、次にネームスペース(これは複数のテーブルを持つ論理データベースと考えてください)を作成し、その中にテーブルを置く必要があります。
aws s3tables create-namespace \ --table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --namespace my_first_namespace awsのs3tablesのcreate-table。 --table-bucket-arn arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --namespace my_first_namespace \ --name my_first_table --format ICEBERG
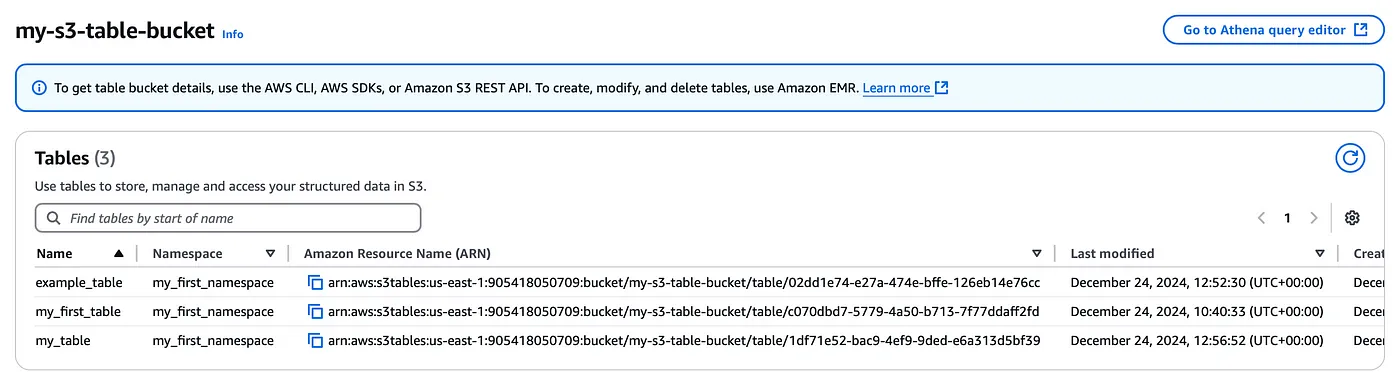
テーブルフォーマットはApache Icebergフレームワークに基づいており、基礎となるストレージはテーブルデータとそのメタデータの両方を持っている。S3テーブルでは、テーブルのメンテナンスを心配する必要はありません。Amazon S3は、S3テーブルまたはテーブルバケットのパフォーマンスを向上させるためのメンテナンスを提供しています。これらのメンテナンスオプションは、ファイル圧縮、スナップショット管理、参照されないファイルの削除です。これらのオプションはデフォルトで有効になっている。メンテナンス設定ファイルを通じて、これらの操作を編集したり無効にしたりすることができる。ただし、メンテナンス・ジョブ・パラメータを 自分に合ったパラメータ値に設定する こともできます。s3tables APIを使用して、ジョブのステータスを確認できます。
aws s3tables get-table-maintenance-job-status \ --table-bucket-arn="arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket" \ --namespace="mynamespace" \ --name="testtable"
S3テーブルを分析サービスと統合する前に、前提条件のステップを完了する必要があります。
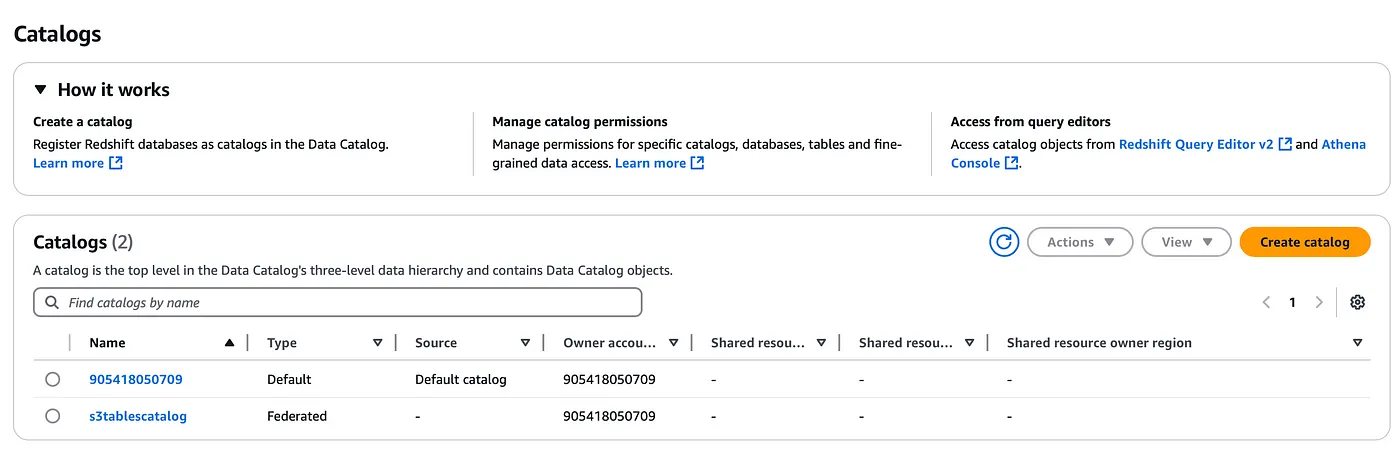
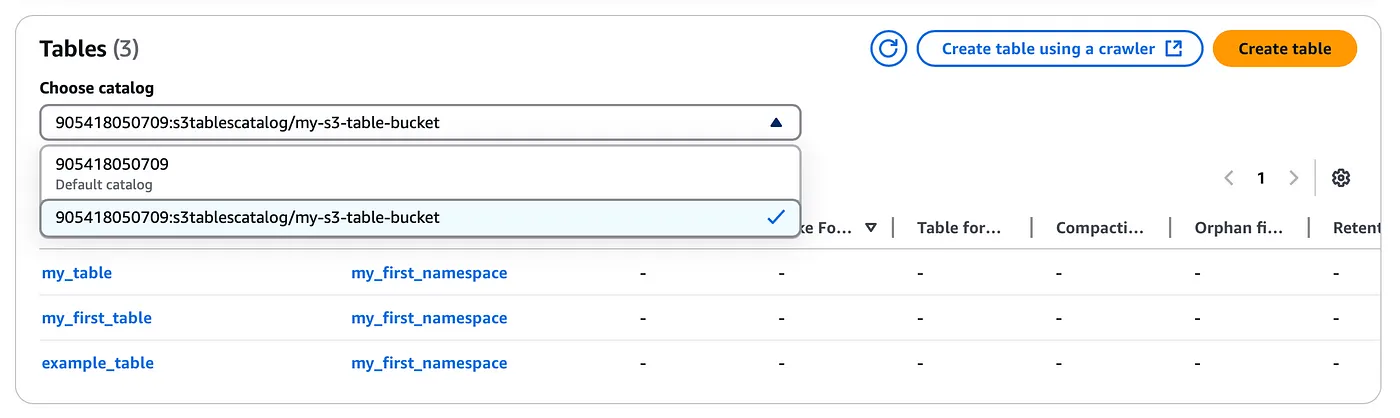
S3テーブル用の新しいカタログを作成する
aws glue create-catalog --region us-east-1 --name s3tablescatalog --catalog-input '{ "CreateDatabaseDefaultPermissions":[], "CreateTableDefaultPermissions":[], "FederatedCatalog": { "Identifier": "arn:aws:s3tables:us-east-1:111122223333:bucket/*", "ConnectionName": "aws:s3tables"}.}'
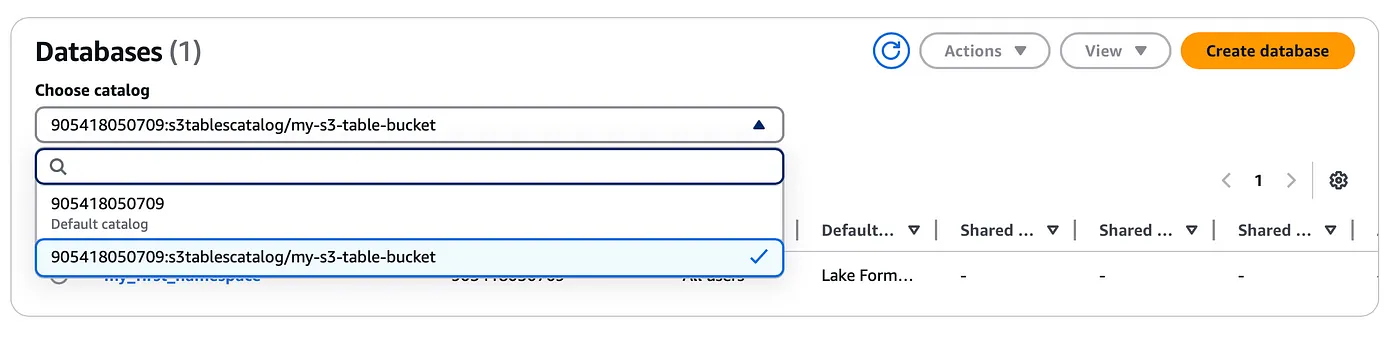
このカタログはAWS LakeFormationの下に登録され、同様にLakeFormationコンソールにネームスペースと先ほど作成したテーブルが表示されるはずです(ドロップダウンオプションを使用して、上記で作成したS3テーブルカタログを選択する必要があります)。
アマゾンEMRとの統合
さて、ここからが楽しいところだ!ここでは、これらのS3テーブルをAWSサービスと統合する。まず、Amazon EMRから始めて、Apache SparkでIceberg対応のEMRクラスタをプロビジョニングする。 そして、SSHを使ってクラスタのプライマリノードにログインする。
スパークシェルをスタートさせる
スパークシェル --packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \ --conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \ --conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \ --conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/my-s3-table-bucket \ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
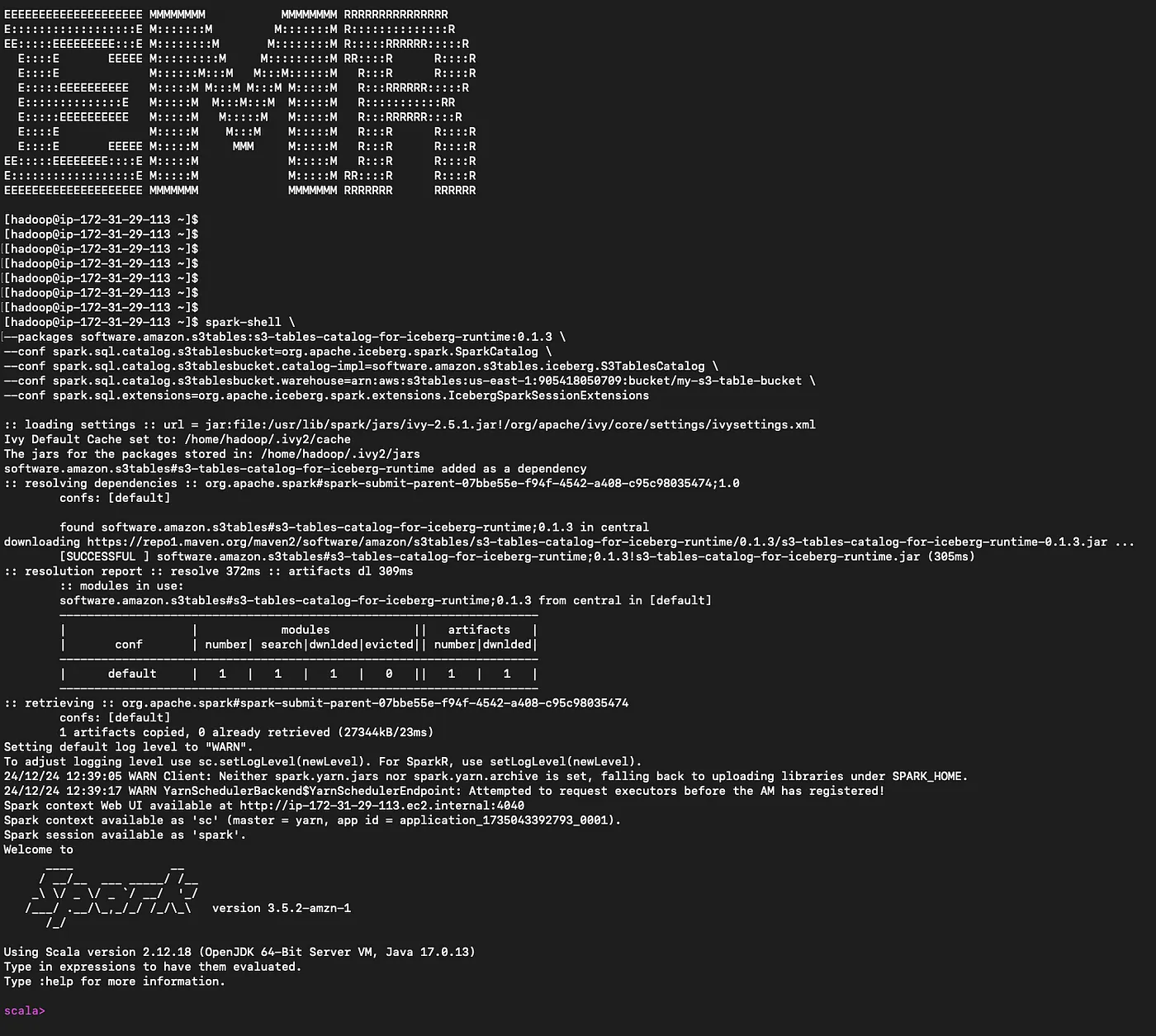
統合のための前提条件に正しく従っていることを確認してください。Amazon EMRの場合、以下のファイルを添付する必要があります。 AmazonS3TablesFullAccessポリシーをEMR_EC2_DefaultRoleに設定し、適切なカタログ、ネームスペース、テーブルレベルの LakeFormation パーミッションも設定します。 EMR_EC2_DefaultRole
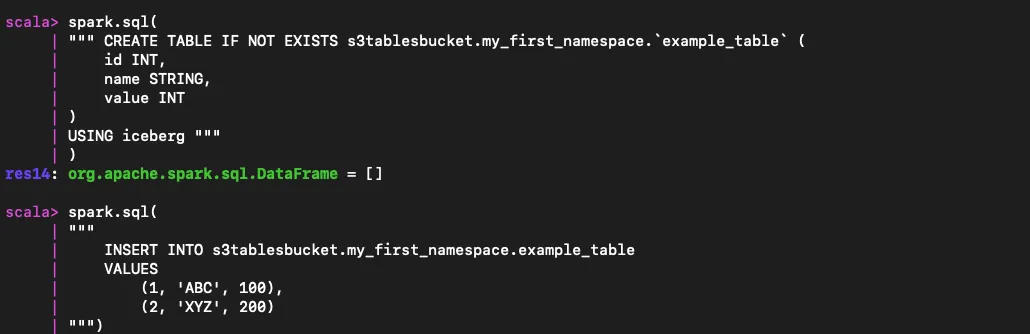
spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.my_first_namespace")
spark.sql(
"""CREATE TABLE IF NOT EXISTS s3tablesbucket.my_first_namespace.`example_table` (
ID INT、
name STRING、
値 INT
)
アイスバーグを使う
)
spark.sql(
"""
INSERT INTO s3tablesbucket.my_first_namespace.example_table
価値
(1, 'abc', 100)、
(2, 'xyz', 200)
""")
spark.sql("" SELECT * FROM s3tablesbucket.my_first_namespace.example_table """).show()


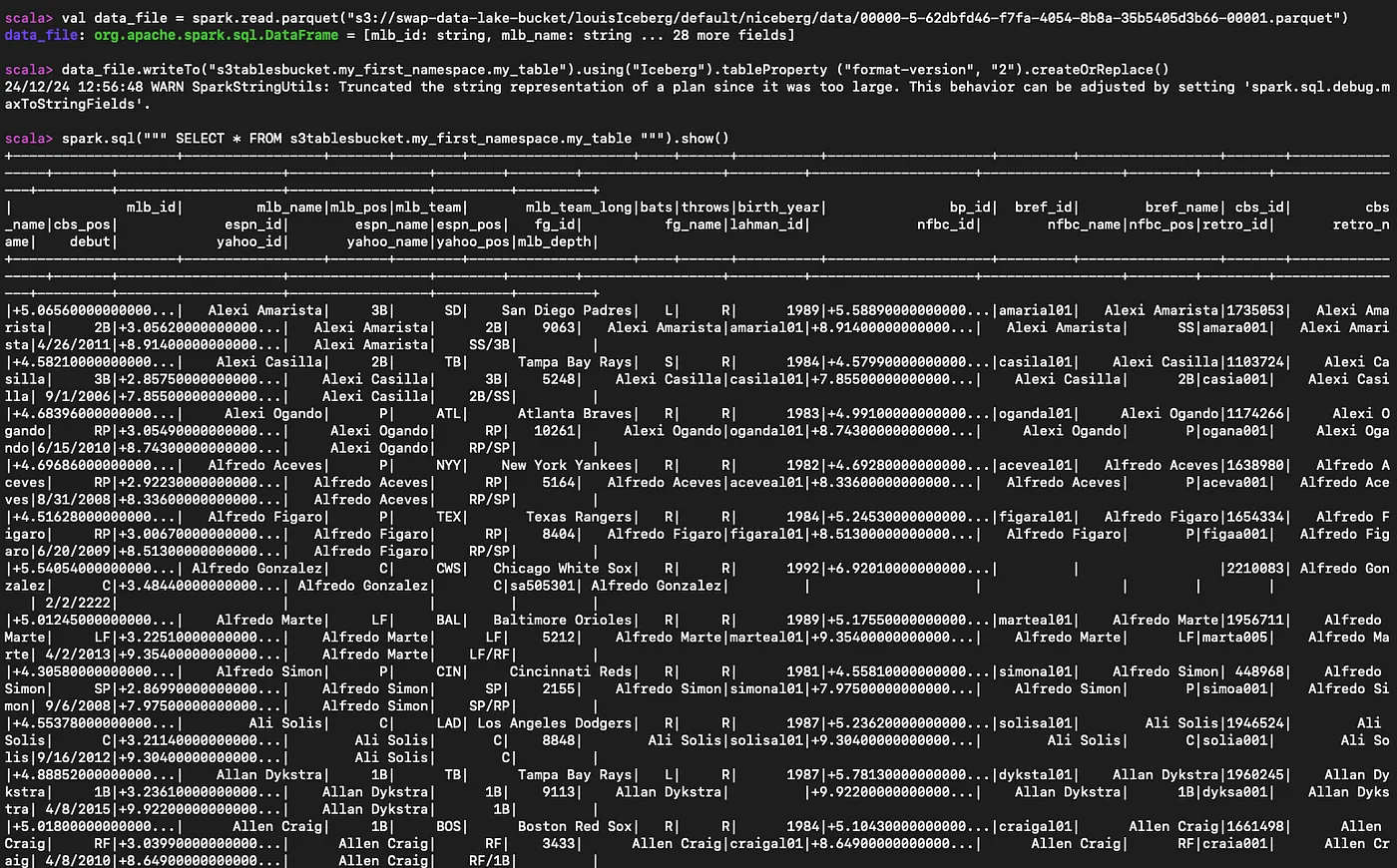
S3上にサンプルパーケットデータがあれば、それを読み込んでS3テーブルを作成し、クエリを実行することができます。
#パレケット・ファイルを読む
val data_file = spark.read.parquet("s3://myBucket/prefix1/file.parquet")
#新しいテーブルを作成する
data_file.writeTo("s3tablesbucket.my_first_namespace.my_table").using("Iceberg").tableProperty ("format-version", "2").createOrReplace()
#作成したテーブルに問い合わせる
spark.sql("" SELECT * FROM s3tablesbucket.my_first_namespace.my_table """).show()
Amazon Athenaとの統合
このテーブルをAmazon Athenaと統合してみよう!S3テーブル用のカタログを作成したので、これはAthenaコンソールのデータソースとカタログの下に表示することができ、s3テーブルを表示するためにエディタのドロップダウンオプションを選択することができます。
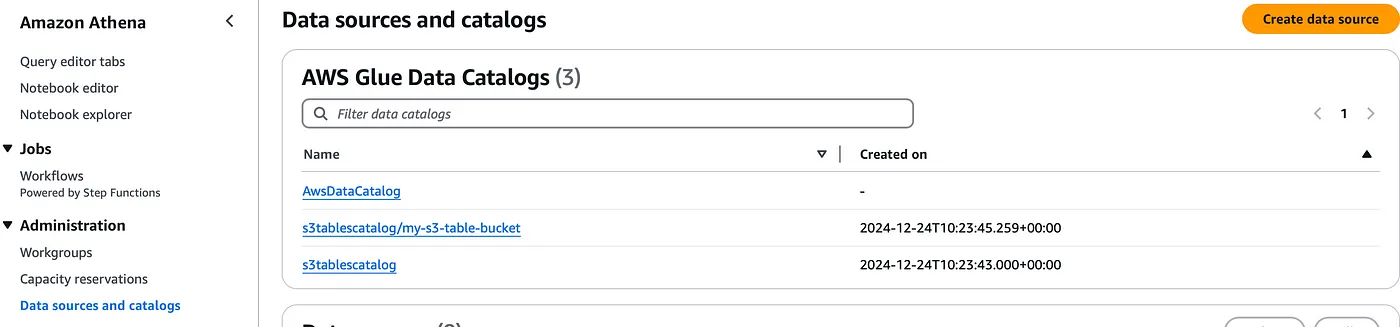
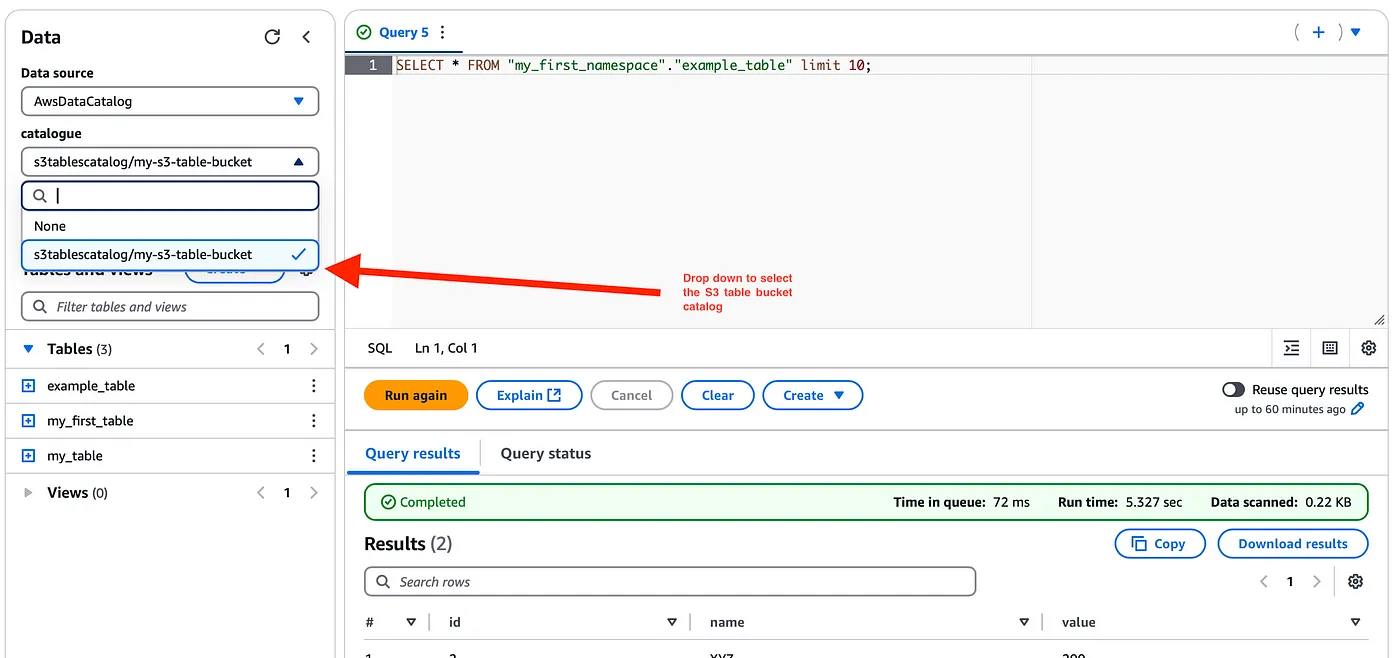
AthenaのネイティブGlueカタログテーブルと同様に、これらのテーブルを簡単にクエリできるようになりました。
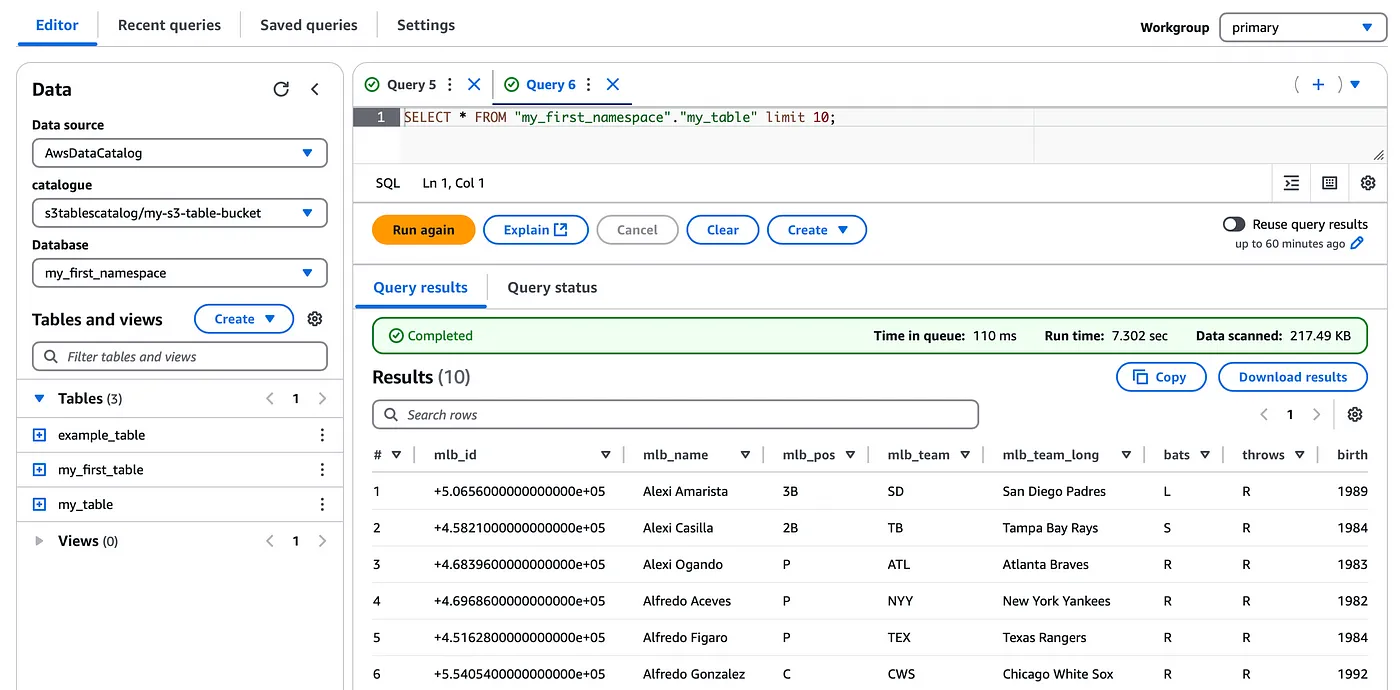
s3 テーブルは S3 によって管理されるため、基礎となる S3 データロケーションにアクセスできず、Amazon Athena ベースのテーブルの Iceberg テーブルメタデータをクエリする場合と同様に、マニフェストファイルをクエリできないことに注意してください。
結論
Amazon S3テーブルを使用すると、読み取りパフォーマンスを最適化するためにパーケットフォーマットで保存されているS3内のデータの上に論理テーブルを作成することができます。これらのテーブルは、ACIDトランザクションをサポートするだけでなく、データの更新、削除、挿入、およびタイムトラベルクエリを実行する機能を提供するIceberg形式に基づいています。これはすべてAmazon S3によって管理され、S3の耐久性、スケーラビリティ、パフォーマンスという付加的なメリットもあります。
もっと詳しくお知りになりたい方、私たちのサービスにご興味のある方は、ご遠慮なくご連絡ください。こちらまでご連絡ください。



