

重要なクラウド・インフラストラクチャの問題に対処しているときは、一刻を争います。迅速かつ正確なサポートが必要です。しかし、急いでいないときでも、貴重な時間を長いフォームの記入に費やすのは避けたいものです。
課題:AIによるサポートをより迅速かつインタラクティブに
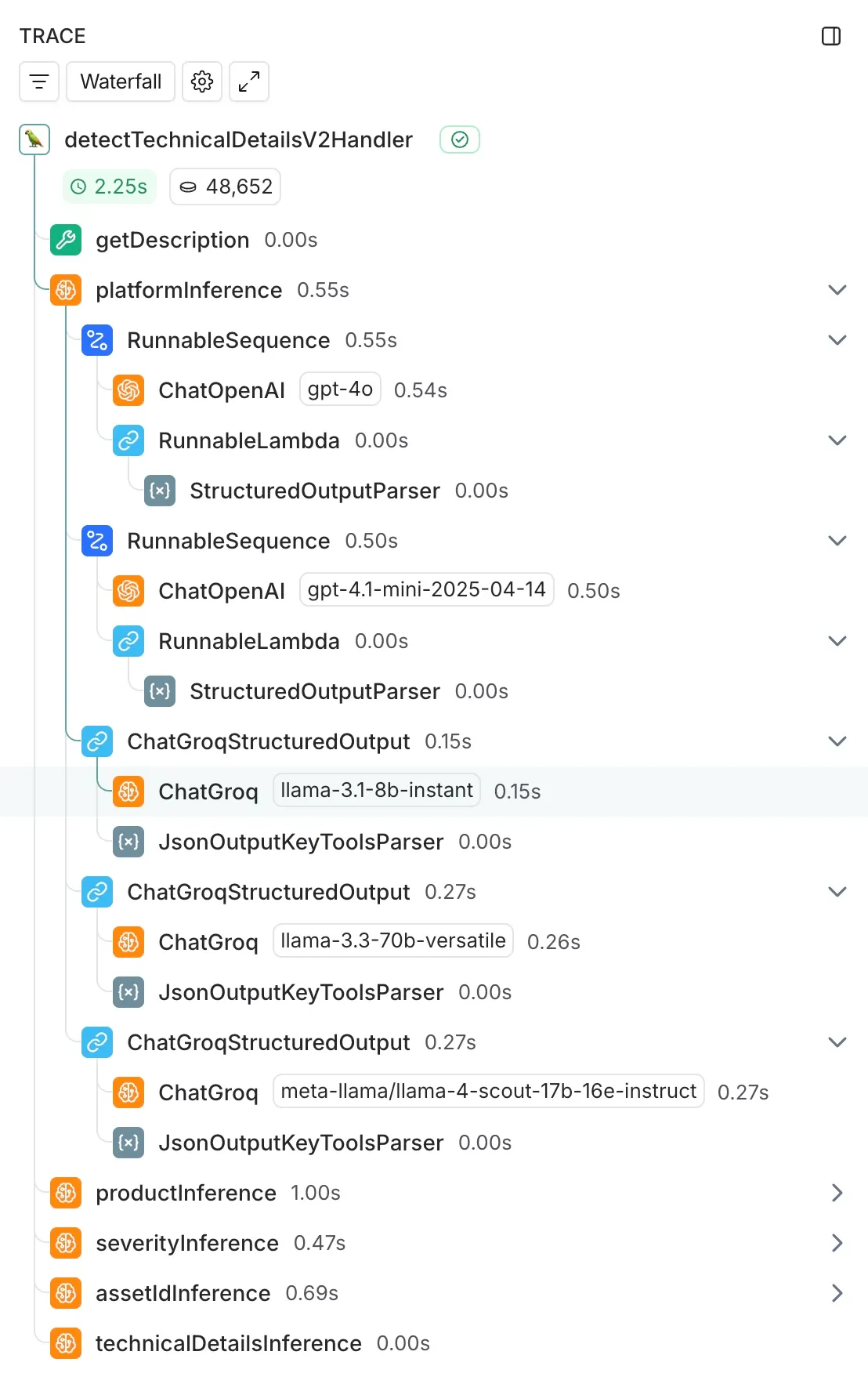
DoiTでは、FinOpsやクラウドに関する問い合わせをサポートするAvaを用意しています。しかし、時には人間の専門家とじっくり話し合いたいこともあるでしょう。このような場合、当社のCase IQシステムが、お客様がケースを開設する際に正しい技術的詳細を提供するのを支援し、当社のカスタマー・リライアビリティ・エンジニア(CRE)が問題を迅速に解決するために必要なすべてを確保します。
このアイデアは2024年夏のハッカソンから生まれ、OpenAIのAPIをベースに構築されました。しかし、私たちは現状を打破し、より良いものを作ろうと決めました。顧客への推薦のレイテンシーに焦点を当て、システムをよりキビキビしたインタラクティブなものにしました。
実験:レイテンシー、コスト、パフォーマンスについて5つのモデルをテスト
これを解決するために、私たちは現在のモデル(OpenAIのGPT-4o)を4つの代替案と比較する2週間の包括的な実験を計画しました:
- GPT-4.1ミニ(OpenAIの新しい高速モデル)
- ラマ 3.1 8B(Groqの専用ハードウェアを使用した小型の超高速モデル)
- ラマ3.3 70B(Groqでより大きく、より高性能なモデル)
- ラマ4 スカウト 17B (メタの最新モデルのプレビューモデル。)
主な目的は、GPT-4oのベースラインよりもレイテンシーの低いモデルを見つけることだった。それを達成するためには、レスポンスの質を(少し)落とすことが予想され、コスト削減は良い副次的な効果だと考えている。
これらのモデルを、エンゲージメント作成時にCase IQが行う5つのタスクでテストしました:
- プラットフォームの検出:リクエストがどのプラットフォームに関するものか
- 製品の識別具体的にどのクラウドサービスに支援が必要か?
- 重大性の評価:この問題の緊急度は?
- 資産の特定:どのプロジェクトまたは勘定が影響を受けるか?
- 技術的な詳細の抽出エンジニアが必要とする具体的な情報とは?
2週間にわたり、755件の実際の顧客エンゲージメントの21,517件のトレースを処理し、レイテンシー、コスト、精度を測定しました。
この比較を容易にした技術的基盤は、既存のLangChain統合でした。すでにGPT-4oの実装にLangChainを使用していたので、比較モデルを追加するのは簡単でした:既存のChatOpenAI統合と一緒にChatGroqコールを追加し、本番システムに影響を与えないように非同期で実行しました。
包括的なインスツルメンテーションのためにLangSmithを活用し、すべてのトレースにわたってレイテンシー測定、トークン使用量、エラー率、入出力ロギングを自動的に取得しました。
結果:わずかな品質の犠牲のためのスピードの向上
結果は期待以上だった:
4~5倍のスピード向上
- プラットフォーム検出:571ms → 249ms(4.1倍高速、Llama 3.3 70Bを使用)
- 製品検出:851ms→406ms(2.1倍速、Llama 3.1 8B使用時)
- 深刻度検出:605ms → 126ms(2.6倍高速化、Llama 3.3 70Bを使用)
- 資産検出:593ms → 220ms(2.7倍高速、Llama 3.3 70Bを使用)
- 技術的な詳細1,914ms → 334ms(5.7倍速、Llama 3.1 8Bを使用)
最大50倍のコスト削減
スピードが第一の目標でしたが、コスト削減は目覚ましく、品質を維持しながら50倍のコストで実行できるタスクもありました。
🎯 パフォーマンスの維持
GPT-4oが92-96%の精度を記録したのに対し、より高速なGPT-4oは強力なパフォーマンスを維持しました:
- ラマ3.3 70B:2~3倍のスピード向上で88~96%の精度
- ラマ3.1 8B:4~5倍のスピード向上で55~88%の精度
勝利の戦略ハイブリッド・アプローチ
単一の "ベスト "モデルを選ぶのではなく、全体的な最適解を得るためには異なるモデルが必要だという結論に達した:
- Llama 3.1 8B製品および技術的詳細の検出(これらのタスクは互いに依存しているため、速度が最も重要なのはここです。)
- Llama 3.3 70B、プラットフォーム、重大度検出、資産識別(Llama 3.1 8Bはこのタスクに苦戦しているようだが、プロンプトによって最適化できる余地があると思われる。)
その結果は?総レスポンスタイムは3秒以上から1秒以下に短縮され、全体として3~4倍のスピードアップとなりました。さらに、このハイブリッド・アプローチにより、総請求額の93%のコスト削減が見込まれています。
これが意味するもの
⚡ほぼ瞬時に回答:クラウドインフラの問題を説明すると、CaseIQはそれを分析し、正しい技術的詳細をほぼ即座に要求できるようになりました。
リアルタイム・サポート・チャンネル:これらのスピードの向上は、新たな可能性を解き放ちます。Slackやその他のメッセージング・プラットフォームに直接サポートを入れることを検討しています。
🚀初回解決率の向上:より正確で完全な問題説明をスペシャリストに提供することで、レスポンスタイムを短縮し、やり取りを減らすことができます。
収穫と今後の課題
技術的な詳細についてはこちらをご覧いただきたい:
- 戦略的なモデル選択が有効慎重なプロバイダーとモデルの選択と賢明なアーキテクチャーの決定を組み合わせることで、劇的なレイテンシーの改善(3秒以上から秒以下)を達成することができ、同時にボーナスとして大幅なコスト削減を実現することができます。
- 人間による評価はかけがえのないものです:自動化されたメトリクスは有用なベースラインを提供するが、テキストと人間を扱う場合、実際のパフォーマンスを理解するためには手作業によるレビューが不可欠である。
DoiTでは、"Powered by technology, perfected by people "を信条としています。このような改善により、お客様がCREから人間の専門知識を必要とするとき、私たちのAIは可能な限り迅速に回答を得るための下準備をすでに済ませています。
-
ケースIQの向上をご自身で体験してみませんか? 今すぐご相談ください今すぐご相談ください。



