あらゆる変革は、計画があってこそ前に進みます。大規模な施策を抱える企業で最大の難所となるのは、どこから着手し、誰を巻き込み、誰と組んで成功させるかという点です。事業部制、マトリクス型、フラット型など組織の形にかかわらず、野心的な目標を掲げてPoC(概念実証)を早期かつ繰り返し回していけば、自然と正しい方向へ進んでいけます。
本記事は、クラウドインフラの構成方法に関する筆者なりの見解に基づくアプローチです。SaaSプロダクトを展開するFinTech(規制業種)企業のクラウド変革をリードし、レガシーアプリケーションをGoogleのマネージドKubernetesサービスであるGKE上で動くよう再設計してきた直近の経験をもとにまとめています。狙いは、ネットワーク、予算、DevOps、セキュリティ、コンプライアンスの各領域で計画・設計しておくべきポイントを浮き彫りにすることです。今後の記事では、ここで触れたトピックの多くを具体例やデモを交えて深掘りしていく予定です。

Google Cloud Platformでエンタープライズ環境を構築する
要点まとめ
- 組織内の足並みをそろえる
- 自分たちに合ったルートを選ぶ
- ユーザーグループ/ロールでアイデンティティを設計する
- 共有VPCでネットワークを集約する
- すべてのリソースを計画的に設計する
- レポーティングを見据えてリソースにタグを付ける
- 予算アラートを設定する
- IaC向けにソースコードリポジトリを整理する
- セキュリティ/モニタリングのアラートを設定する
- Bastion(踏み台)ホストを使う
- データを保護する
- Cloud Security Command Centerを活用する
- 災害復旧・事業継続計画を文書化し、テストする
- 経験豊富なエキスパートと組む
組織内の足並みをそろえる
本記事はGoogle Cloud Platform(GCP)の機能を中心に扱いますが、AWSのCEOであるAndy Jassy氏が、クラウド変革を成功に導く——いや、あらゆる施策を成功させる——4つの鍵を見事に整理している点には触れておかねばなりません。
- 経営トップ層の確信と足並みのそろい
- トップダウンの野心的な目標
- ビルダー(エンジニア)を育てる
- 分析麻痺で着手前に立ち止まらない
新しいことに挑むときの私自身のモットーは、「まず動かす、次に正しくする、それから速くする」です。
自分たちに合ったルートを選ぶ
Googleはエンタープライズ向けのベストプラクティスに関する優れた資料を公開しており、下図ではセキュアなGoogle Cloudサービスを実現するための推奨ステップが示されています。組織ごとにニーズは異なりますが、このロードマップは具体的なインフラ計画を立てたり、利用できる選択肢を把握したりする上での絶好の出発点になります。
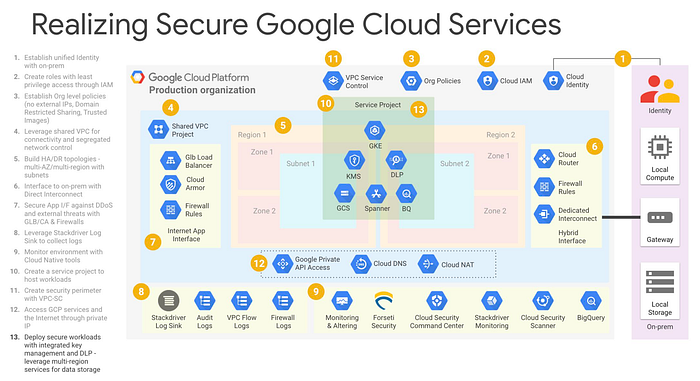
出典:Google
ユーザーグループ/ロールでアイデンティティを設計する
まずは最小権限のポリシーから始め、組織レベルでのプロジェクト作成権限はただちに無効化しましょう。この権限を持つのはDevOps、Billing、OrgAdminsだけにとどめ、理想的にはインフラ自動化(Terraformなど)用のDevOps配下のサービスアカウントだけに限定します。可能な限り、IAMに個人アカウントを直接追加することは避けてください。
- Organization Administrators([email protected])
- Network Administrators([email protected])
- Security Administrators([email protected])
- Billing Administrators([email protected])
- DevOps([email protected])
- Development([email protected])
- DataScience([email protected])[任意]
これらのグループを作成したら(Cloud Identityを使って既存のADやIdPと連携してもよいですし、GSuite組織内で作成しても構いません)、各グループに少なくとも1名を割り当てます。その上で、組織レベルまたはフォルダレベルで、各グループに必要なときにのみ必要なロールを付与していきます。
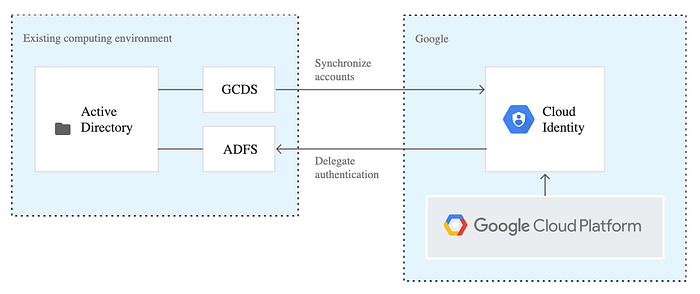
出典:Google
GitOpsを採用していれば、開発チームはソース管理からのCI/CDパイプライン経由で、それぞれのKubernetesクラスタの名前空間に任意のworkloads*をデプロイできます。このアプローチによってアクセス権とクォータを管理しやすくなり、クラウドコストの統制と予算管理がぐっとシンプルになります。
*信頼できるプライベートイメージリポジトリ内の承認済みバイナリのみ
共有VPCでネットワークを集約する
規制の厳しい業界や、SOC 2のようなコンプライアンスを維持する場面では、統制要件として厳格な責務の分離が求められることがあります。エンタープライズで一般的なやり方のひとつが、ネットワーク管理をDevOpsやアプリケーション開発から切り離すことです。GCPでは共有VPCと、ホストプロジェクト・サービスプロジェクトという洗練されたプロジェクト階層機能のおかげで、これを容易に実現できます。
ネットワークは衝突を避けるよう設計・計画し、プロジェクト内のデフォルトネットワークはすべて削除しましょう——後できっと「やっておいてよかった」となります!
繰り返しになりますが、これはあくまで筆者の見解に基づくアプローチであり、皆さんのケースとは異なるかもしれません。私の推奨するベストプラクティスは、サービスプロジェクトをホストプロジェクトでカプセル化し、ネットワーク設定を一箇所に集約した上で、これらのプロジェクトへのアクセス権はネットワーク管理者グループだけに付与することです。
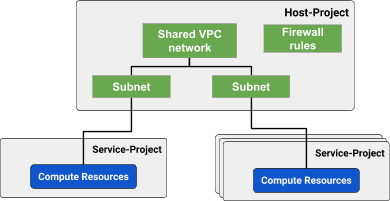
サブネットへのIP割り当ては、規模や成長計画にもよりますが、VPCあたり/16のCIDRレンジを確保しておけばまず十分です(約65,000アドレス)。一方Kubernetesは、一時的なコンテナに対して動的にIPを割り当てる仕組みのため、サービスやPod用に多数のIPを必要とします。以下のように、セカンダリIP用に未使用のレンジを別途ブロックして確保しておくことをおすすめします。
- VPC /16レンジ内のサブネット:k8s-nodes-prod (10.10.0.0/22)
secondary: k8s-services-prod (10.80.64.0/22)
secondary: k8s-pods-prod (10.80.0.0/18)
subnet: bastion-prod (10.10.64.0/29)
- VPC /16レンジ内のサブネット:k8s-nodes-stage (10.11.0.0/22)
secondary: k8s-services-stage (10.81.64.0/22)
secondary: k8s-pods-stage (10.81.0.0/18)
subnet: bastion-stage (10.11.64.0/29)
- VPC /16レンジ内のサブネット:k8s-nodes-demo (10.12.0.0/22)
secondary: k8s-services-demo (10.82.64.0/22)
secondary: k8s-pods-demo (10.82.0.0/18)
subnet: bastion-demo (10.12.64.0/29)
- VPC /16レンジ内のサブネット:k8s-nodes-qa (10.13.0.0/22)
secondary: k8s-services-qa (10.83.64.0/22)
secondary: k8s-pods-qa (10.83.0.0/18)
subnet: bastion-qa (10.13.64.0/29)
- VPC /16レンジ内のサブネット:k8s-nodes-dev (10.14.0.0/22)
secondary: k8s-services-dev (10.84.64.0/22)
secondary: k8s-pods-dev (10.84.0.0/18)
subnet: bastion-dev (10.14.64.0/29)
こうしておけば、データベースサーバーやその他のリソース用に追加サブネットを切る余裕がVPC内に十分残ります。
すべてのリソースを計画的に設計する
Google Cloud Platformでは、リソースが組織・フォルダ・プロジェクトの階層で整理されます。そのおかげで、他クラウドにありがちなマルチアカウント地獄に陥らずに、ユーザーやグループを管理できます。早期からクラウドを導入した多くの企業は、こうしたアカウントと権限の「混沌」を維持するためにカスタムソリューションを組まざるを得なくなり、InfoSecとコンプライアンスの観点で悪夢のような状態に陥っています——その点、GCPの設計は正解だと言えるでしょう。
├── DevOps
│ └── project-devops
│ ├── bucket-terraform-state
│ ├── cluster-devops
│ │ ├── namespace-cicd
│ │ └── namespace-vault
│ ├── sink-application-logs
│ └── sink-audit-logs
├── RnD
│ ├── Non-Production
│ │ └── project-shared-network-nonprod
│ │ ├── sink-application-logs
│ │ ├── sink-audit-logs
│ │ ├── vpc-demo-10-12-0-0
│ │ │ └── project-demo
│ │ │ ├── cluster-demo
│ │ │ │ ├── namespace-team1
│ │ │ │ ├── namespace-team2
│ │ │ │ └── namespace-vault
│ │ │ ├── sink-application-logs
│ │ │ └── sink-audit-logs
│ │ ├── vpc-dev-10-14-0-0
│ │ │ └── project-development
│ │ │ ├── cluster-development
│ │ │ │ ├── namespace-team1
│ │ │ │ ├── namespace-team2
│ │ │ │ └── namespace-vault
│ │ │ ├── sink-application-logs
│ │ │ └── sink-audit-logs
│ │ └── vpc-qa-10-13-0-0
│ │ └── project-development
│ │ └── cluster-qa
│ │ ├── namespace-team1
│ │ ├── namespace-team2
│ │ └── namespace-vault
│ ├── Production
│ │ └── project-shared-network-prod
│ │ ├── sink-application-logs
│ │ ├── sink-audit-logs
│ │ ├── vpc-prod-10-10-0-0
│ │ │ └── project-production
│ │ │ ├── cluster-production
│ │ │ │ ├── namespace-team1
│ │ │ │ ├── namespace-team2
│ │ │ │ └── namespace-vault
│ │ │ ├── sink-application-logs
│ │ │ └── sink-audit-logs
│ │ └── vpc-stage-10-11-0-0
│ │ └── project-stage
│ │ ├── cluster-stage
│ │ │ ├── namespace-team1
│ │ │ ├── namespace-team2
│ │ │ └── namespace-vault
│ │ ├── sink-application-logs
│ │ └── sink-audit-logs
│ └── project-monitoring
│ ├── bucket-development-logs
│ ├── bucket-production-logs
│ ├── workspace-development
│ └── workspace-production
└── Security
└── project-security
└── bucket-audit-logs
レポーティングを見据えてリソースにタグを付ける
パブリッククラウドで多くの企業が頭を悩ませるのが、課金、レポーティング、コスト管理です。コストを抑える有効な手段のひとつが、先ほど示したようにチーム単位の名前空間でインフラを設計することです。これにより開発者のオンボーディングが速くなって生産性も上がり、急峻な学習曲線や限られた人材プールの問題も避けられます。もうひとつのベストプラクティスは、リソースにタグやラベルを付けておき、後からアラート・予算・レポートを設定できるようにしておくことです。
同僚のひとりが、当社のオープンソースツールIRISを使った「Auto Tagging Google Cloud Resources」という記事を書いています。このテーマには優れた記事が他にも数多くあるので、タグの設計は早めに行い、後々のトラブルを最小限に抑えましょう。
リソースごとに付けておきたいタグの例:
- Owner — 現在の責任者(チーム異動している可能性あり)
- Creator — 最初に作成した人(後から確認したいことが出てくる場合あり)
- Project — 例:my-company-production(グルーピングのため)
- Working Hours — Zoryaで開発リソースを自動スケジューリングすれば最大60%のコスト削減が可能
予算アラートを設定する
多くのCFOがクラウドを敬遠する理由は、可視性の低さと、設定ミスによる支出の青天井リスクにあります。予算アラートを活用すれば、日々の支出を追跡し、クラウド支出を企業収益と整合させるべく素早く手を打てます。コスト情報を各チームに共有し、チームリーダー同士で集まって予算をモニタリングする運用を習慣づけるのは、おすすめのやり方です。
IaC向けにソースコードリポジトリを整理する
リソース階層の計画ができたら、次に直面するのが「鶏が先か卵が先か」のジレンマです。すべてをTerraformでプロビジョニングするとして、そのTerraform自身が全リソースを構築するための権限をどう取得するのか、という問題です。私のおすすめは、Org AdminがDevOpsフォルダとプロジェクトを作成し、DevOpsチームがプロジェクトの作成/削除などに必要な権限を持つTerraform用のサービスアカウントを作る流れです。最初は最低限の権限から始め、エラーが出たら必要なロールを都度追加していきましょう。
同僚のひとりが書いた「Refactoring Terraform The Right Way」は素晴らしい記事で、Terragruntの作者であるGruntwork.ioのエキスパートチームの提言とも一致しています。要するに、リソース・サービス・ライブ環境を3つの別々のリポジトリに分け、ソース管理側でグループ権限を適切に管理しよう、という話です。
セキュリティ/モニタリングのアラートを設定する
モニタリングとアラートは計画段階のいちばん最初に置くべきテーマですが、ありがたいことにGoogle Cloud Platformにはこれを楽にしてくれる組み込み機能が数多くあります。後述するCloud Security Command Center(CSCC)のCISベンチマークスキャンは、不足しているモニタリングを検出し、各プロジェクトを正しく構成するための手順をステップごとに示してくれます。CSCCの詳細は後述します。
参考までに、推奨モニタリング設定をまとめたGistはこちらです。
アクセスにはBastion(踏み台)ホストを使う
分かりやすさのため上図ではBastionホスト用のVMを省略しましたが、セキュアなアクセスのベストプラクティスはBastionホストの利用です。プロジェクトごとにBastionホストVM用のサブネットレンジを切り、外部IPはすべて排除してプライベートクラスタを構成することをおすすめします。インスタンス数1のマネージドインスタンスグループにしておけば、障害時にもGCPが新しいインスタンスを自動で立ち上げてくれます。BastionへはVPN経由で接続することも、より現代的でセキュアなCloud Identity Aware Proxy(IAP)を使うこともできます。さらにユーザーのSSHキーを制限すれば、Bastionをよりいっそう堅牢にできます。
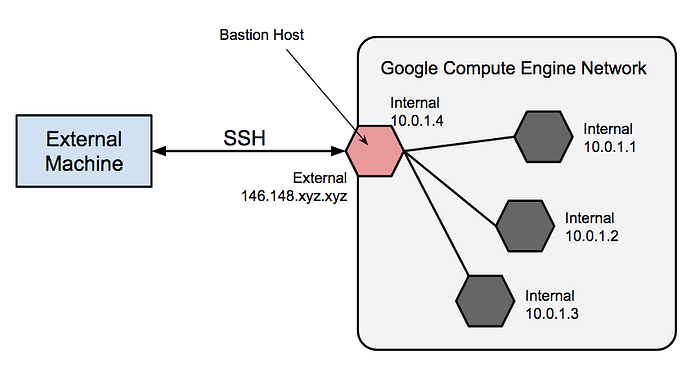
出典:Google
Kubernetesのベストプラクティスに関する記事は数多くありますが、Googleのエンジニアが書いた「Completely Private GKE Clusters With No Internet Connectivity」はよい参考になり、上で提案した基本構成を裏付ける内容にもなっています。
データを保護する
インフラは、組織のセキュリティチームが定めたポリシーを満たすよう計画・設計する必要があり、多くの場合さまざまなレベルの暗号化要件が伴います。GCPのリソースは既定で保管時に暗号化されますが、保管時・転送時の暗号鍵に関するニーズ(Google管理、自社管理、BYOK)は明確にしておきましょう。
また、組織内のデータへのアクセスを、個人やアプリケーション単位まで分離したい場合もあるはずです。これは下図のようにVPC Service Controlsで実現できます。
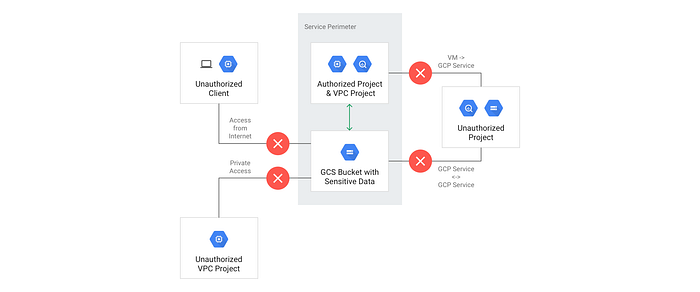
リソース階層の例で示したようにモニタリング目的でログやデータを送出する場合は、ログシンクを構成してCloud Data Loss Prevention(Cloud DLP) APIを活用し、保存前に約100種類のPIIデータを除去するようにしておくのも有効です。
Cloud Security Command Centerを活用する
GCPの隠れた逸品のひとつがCloud Security Command Centerです。アセット管理、脅威・異常検知、WAF、脆弱性スキャンを単一のコンソールから扱える統合ビューを提供します。個人的にいちばん気に入っているのはスキャン機能です——スキャン対象のプロジェクトは選べますが、スキャンのタイミングは制御できません(1日1〜2回)。すべてのプロジェクトとリソースについて、CISおよびNISTベンチマークの違反箇所を可視化し、ステップごとの修復手順を提示してくれます。
注:新しい料金体系では、CSCCが2つのティア(無料・プレミアム)に分かれます。
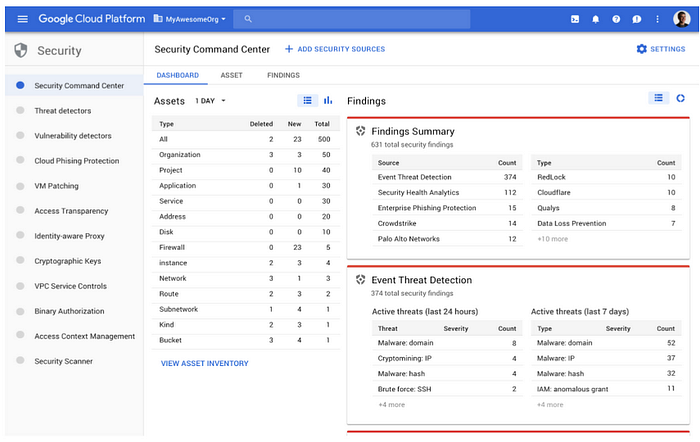
Cloud Security Command Center — 出典:wideops.com
- 役立つリソース/チェックリストとして、Google Cloud向けCISベンチマークがあります——Kubernetesやその他のシステム向けのベンチマークもあり、いずれも無料で利用できます。
そのほか、構成やコードデプロイの最適化に役立つ優れたサードパーティツールとして、Forseti SecurityやPalo Alto NetworksのPrisma Cloud(旧TwistlockおよびRedlock)もあります。
災害復旧・事業継続計画を文書化し、テストする
言うまでもありませんが、バケットでもデータベースでも、すべてのデータについて自動化されたバックアップ&リカバリ計画を備えておく必要があります。バックアップとリストアの手順は少なくとも年1回、できればもっと高い頻度で実地に訓練しておきましょう。
事業継続性と安心感のためには、Terraformを使ってインフラをコード(IaC)として定義することを強くおすすめします。インフラの状態を規律をもってコードで維持できていれば、コンプライアンス監査用のレポートを容易に出力でき、致命的な障害からも迅速に復旧できます。
経験豊富なエキスパートと組む
エンタープライズのクラウド変革で押さえるべきポイントの、ほんの表面をなぞったに過ぎませんが、圧倒されそうに感じても、最善の対策はとにかく着手することです。手前味噌ではありますが、成功確率を高めるための次善策は、何度も同じことをやり遂げてきたプロフェッショナルとチームを組むことです。
DoiT Internationalは、アーキテクチャレビュー、エキスパートサポート、独自のクラウド予算・レポートツールにより、これまで数千社のクラウド活用を支援してきました——しかもこれらはすべて、お客様に追加費用なしで提供しています(当社はクラウドリセラーパートナーです)。私たちのゴールは、皆さんのチームがクラウドインフラを自走で運用できるようスキルアップを支援し、エンパワーすることですが、必要なときにはいつでもおそばにいます。
Mikeの記事をもっと読みたい方は、Mediumのブログをご覧いただくか、TwitterでMikeをフォローしてみてください。