In precedenza questa funzionalità si chiamava Workload Identity, mentre Workload Identity Federation ( WIF) era il nome di una funzionalità analoga che permetteva alle identità esterne di accedere alle risorse all'interno di GCP.
Di recente, GCP ha deciso di far confluire Workload Identity sotto il cappello di Workload Identity Federation. Oltre al cambio di nome, ora è possibile fare riferimento alle entità Kubernetes (cluster, service account) direttamente come principal IAM. Questo semplifica la configurazione di WIF per GKE, perché elimina la necessità di un Google Service Account ( GSA) dedicato e di binding aggiuntivi, ma ne parleremo più avanti.
In questo articolo vedremo la nuova Workload Identity Federation for GKE e come incide sui workloads già in esecuzione che utilizzano i binding di Workload Identity.
Cos'è Workload Identity Federation?
WIF è una funzionalità pensata per fare da ponte tra i sistemi di identità esterni e Google Cloud IAM. Permette alle organizzazioni di estendere senza attriti la propria infrastruttura di identità — Active Directory, AWS, Okta e altre — alle risorse di Google Cloud.
Stabilendo relazioni di trust tra i provider di identità esterni (IdP) e Google Cloud IAM, WIF consente a utenti e applicazioni autenticati tramite sistemi diversi da GCP di accedere alle risorse GCP con le proprie identità preesistenti.
Per stabilire questa relazione di trust occorre prima creare un Workload Identity Pool per gestire le identità esterne, e poi aggiungere al pool dei Workload Identity Provider, ciascuno dei quali descrive la relazione tra il proprio IdP e GCP.
Una volta stabilita la relazione, un token di credenziali rilasciato dall'IdP può essere verificato dal Security Token Service di Google e scambiato con un token federato per autenticarsi su GCP.
In Workload Identity Federation for GKE (in precedenza chiamata semplicemente Workload Identity) è Google a gestire pool e provider per conto dell'utente.
Ogni progetto GCP dispone di un singolo pool fisso (PROJECT_ID.svc.id.goog) e, una volta abilitato su un cluster GKE, quest'ultimo viene registrato come provider di identità su quel pool.
Il GKE metadata server viene poi distribuito automaticamente come DaemonSet su tutti i nodi del cluster. Tra le altre cose, serve a intercettare le richieste provenienti dai workloads e a rispondere con il token corretto per il service account che il workload è configurato per impersonare.
Concedere autorizzazioni IAM ai workloads su GKE
È sostanzialmente questo il senso dell'intera funzionalità: permettere ai workloads su GKE di accedere alle risorse GCP senza dover passare credenziali esplicite né appoggiarsi all'IAM Service Account del nodo sottostante.
Per prima cosa occorre abilitare WIF sul proprio cluster GKE e sui node pool, se non lo si è già fatto, ma il procedimento è ben documentato ed esula dallo scopo di questo articolo.
Fatto questo, occorre creare un Kubernetes Service Account ( KSA) da associare al workload (configurandolo nella spec del Pod).
Quindi, con Workload Identity ( WI) è possibile concedere ai workloads i permessi IAM di GCP in due modi:
Tramite l'impersonificazione di un Google IAM Service Account
Fino a poco tempo fa era l'unico modo standard per configurare WI; ora è documentato come metodo alternativo.
In sintesi, occorre creare un Google Service Account ( GSA) e assegnargli tutte le autorizzazioni IAM necessarie al workload. Bisogna poi creare un binding tra GSA e KSA, attribuendo al KSA il ruolo roles/iam.workloadIdentityUser sul GSA, e annotando il KSA di conseguenza.
Tramite identificatori di principal IAM
Si tratta di una funzionalità di rilievo e di una novità recente, come accennato nell'introduzione. Le risorse Kubernetes possono essere referenziate direttamente nelle policy IAM come principal.
È possibile fare riferimento al KSA per nome (sfruttando l'identity sameness) oppure per UID (disponibile nella spec del KSA dopo la creazione).
Si possono persino indirizzare tutti i pod di un cluster, qualora vi sia un permesso IAM comune a tutti i workloads.
Configurare Workload Identity: impersonificazione GSA o identificatori di principal IAM
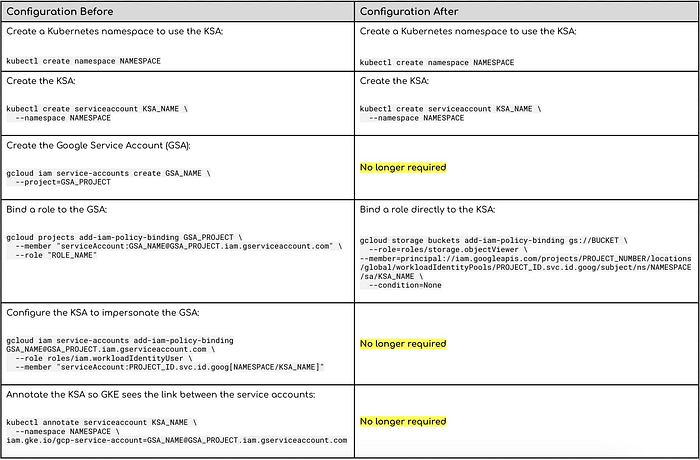
Fonte: https://twitter.com/_techcet_/status/1773865010651173293
Come mostra la tabella sopra, la possibilità di indirizzare le risorse Kubernetes come principal IAM ha semplificato sensibilmente la configurazione.
Anziché dover gestire un GSA aggiuntivo e ricordarsi di concedere al KSA il permesso di impersonarlo (un passaggio spesso dimenticato), è possibile assegnare i ruoli IAM necessari direttamente al KSA. Non serve più nemmeno annotare il KSA con il nome del GSA, un altro passaggio facile da configurare male o da scordare.
Poter fare riferimento a un KSA tramite UID anziché tramite nome è un'aggiunta apprezzabile, perché riduce il rischio di concedere accidentalmente l'accesso a workloads indesiderati attraverso l'identity sameness. D'altra parte, l'identity sameness, se sfruttata bene, può essere a sua volta una funzionalità utile, ed è praticabile in entrambe le versioni della configurazione.
Inoltre, la possibilità di fare riferimento a tutti i pod di un cluster come un set di principal IAM è una funzionalità preziosa che garantisce maggiore flessibilità. Sono certo che nei prossimi mesi vedremo aggiungere il supporto per altri tipi di risorse Kubernetes come principal IAM (i namespace sarebbero un'ottima aggiunta).
Un limite dell'utilizzo dei principal IAM è che vi sono ancora alcuni servizi non supportati o in preview. Se attualmente si utilizza WI per accedere a uno di questi servizi, conviene rimandare l'aggiornamento della configurazione.
Migrare la configurazione esistente verso i principal IAM
La buona notizia è che non è obbligatorio: il metodo basato sull'impersonificazione GSA è ancora supportato e non credo verrà dismesso a breve.
Ciò detto, l'utilizzo dei principal IAM semplifica la configurazione e offre alcuni vantaggi aggiuntivi, come illustrato nella sezione precedente, perciò consiglio di adottarlo dove possibile.
Qual è il modo meno invasivo per migrare i workloads dalla configurazione attuale all'utilizzo dei principal IAM?
Supponendo che si stia già utilizzando Workload Identity per accedere alle risorse GCP, si avrà un GSA con i permessi IAM necessari e un KSA con il ruolo IAM Workload Identity User su quel GSA.
Infine, il KSA sarà annotato in modo da puntare al GSA, ad esempio:
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
iam.gke.io/gcp-service-account: <GSA_NAME>@<PROJECT_ID>.iam.gserviceaccount.com
...
Vediamo se è possibile eseguire un aggiornamento "zero-downtime" della configurazione di WI.
Per prima cosa, avviamo un pod che utilizza quel KSA per eseguire alcuni test
$ echo 'apiVersion: v1
kind: Pod
metadata:
name: workload-identity-test
spec:
serviceAccountName: <KSA_NAME>
containers:
- image: google/cloud-sdk:slim
command: ["sleep","infinity"]
name: workload-identity-test' | kubectl apply -f -
Quando il pod è pronto e in esecuzione, possiamo accedervi con exec
$ kubectl exec -ti token-test -- bash
Dall'interno del pod, possiamo fare una richiesta al metadata server per vedere quale identità sta utilizzando il pod
root@token-test:/# curl -H "Metadata-Flavor: Google" http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/?recursive=true
{"aliases":["default"],"email":"<GSA_NAME>@<PROJECT_ID>.iam.gserviceaccount.com","scopes":["https://www.googleapis.com/auth/cloud-platform","https://www.googleapis.com/auth/userinfo.email"]}
Dal campo email nella risposta si vede che l'identità corrisponde al GSA che il KSA è configurato per utilizzare (tramite l'annotazione sul KSA).
Cosa accadrebbe se rimuovessimo quell'annotazione dal KSA?
# questo viene eseguito al di fuori del pod
$ kubectl annotate serviceaccount <KSA_NAME> iam.gke.io/gcp-service-account-
Riproviamo la richiesta
root@token-test:/# curl -H "Metadata-Flavor: Google" http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/default/?recursive=true
{"aliases":["default"],"email":"<PROJECT_ID>.svc.id.goog","scopes":["https://www.googleapis.com/auth/cloud-platform","https://www.googleapis.com/auth/userinfo.email"]}
Come si vede, l'identità passa immediatamente al Workload Identity Pool del progetto. Questo dovrebbe significare che il passaggio dall'impersonificazione GSA al binding tramite principal IAM può avvenire senza nemmeno riavviare i pod (va detto che alcuni client potrebbero richiedere un riavvio per iniziare a usare la nuova identità).
Dato che il KSA è ancora annotato con il GSA e il workload è funzionante:
- Creare la policy IAM per concedere i ruoli IAM necessari direttamente al KSA (gli stessi ruoli concessi al GSA)
- Rimuovere l'annotazione WI dal KSA; a questo punto il pod dovrebbe iniziare immediatamente a utilizzare i permessi concessi al principal del KSA (in caso di errori, un riavvio del pod dovrebbe risolverli)
- Una volta verificato che tutto funzioni, è possibile eliminare il GSA ormai ridondante e assicurarsi che IaC e manifest siano allineati
Il cambio di nome da Workload Identity a Workload Identity Federation for GKE all'inizio è stato un po' spiazzante, perché tra le due funzionalità c'è sempre stata una distinzione netta. Tuttavia, il nuovo supporto per i principal IAM avvicina WIF for GKE al resto di WIF e chiarisce la direzione in cui si muove questa funzionalità.
Se ancora non utilizza WIF, abilitarla e usarla nei propri cluster GKE è oggi molto più semplice. Se invece la utilizza già, aggiornare la configurazione esistente al nuovo metodo richiede pochissimo sforzo e permette di ripulire alcune risorse superflue, oltre a risparmiare righe di configurazione nell'IaC.
Se sta riscontrando difficoltà nella configurazione di WI, dia un'occhiata al nostro progetto workload-identity-analyzer su GitHub ( supporto per i principal IAM in arrivo).