El Horizontal Pod Autoscaler (HPA) de Kubernetes cambió la forma de gestionar los workloads al escalar automáticamente los pods de deployments y statefulsets, hacia arriba o hacia abajo, según el uso promedio de CPU, el uso promedio de memoria o cualquier otra métrica personalizada que definas para responder a la demanda.
Implementación actual
Al calcular el uso de recursos de los pods, el valor total se obtiene sumando el uso de cada contenedor dentro del pod. Sin embargo, este método no siempre resulta adecuado para workloads en los que el uso de los contenedores no está estrechamente relacionado o no varía al mismo ritmo.
Por ejemplo, un contenedor sidecar que gestiona logs puede consumir pocos recursos, mientras que el contenedor principal de la aplicación de blog se encarga de la mayor parte del workload. El HPA no escalaría según el uso del contenedor crítico, ya que la métrica promedio del pod podría no reflejar la realidad.
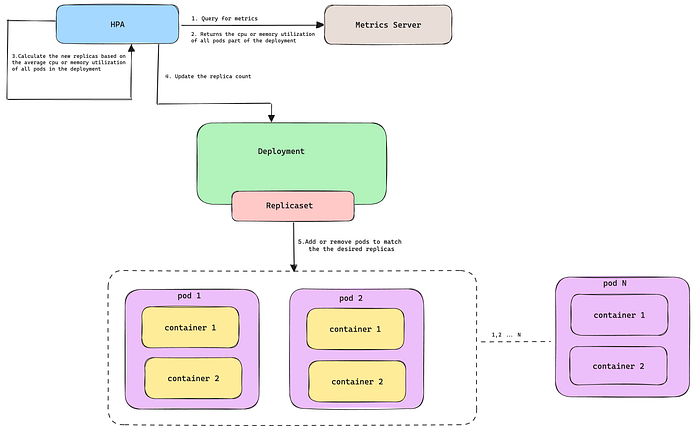
Escalado del HPA según el uso promedio de recursos de todos los pods de un deployment
Nueva implementación
Introducida en Kubernetes v1.20 y ya estable en v1.30, la funcionalidad de métricas de recursos por contenedor permite que el HPA tome como referencia las métricas de un contenedor específico dentro de un pod. Puedes configurar el HPA para que escale según el uso de recursos (CPU, memoria, etc.) de un contenedor concreto del pod.
Esta funcionalidad ayuda a asignar recursos de forma eficiente y a evitar escalados innecesarios disparados por el alto uso de un pod a causa de contenedores no críticos. Al monitorear el consumo de recursos del contenedor que sostiene la funcionalidad principal, te concentras en el workload real. Así se toman mejores decisiones de escalado y se previenen cuellos de botella en el rendimiento.
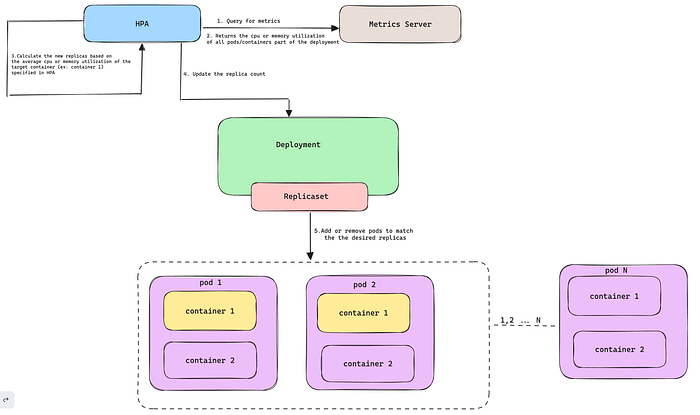
Escalado del HPA según el uso promedio de recursos del contenedor objetivo en todos los pods de un deployment
En este blog te muestro cómo aprovechar las métricas de recursos por contenedor para escalar tus deployments en un pod con varios contenedores.
Requisitos previos
- Un cluster de Kubernetes con versión 1.27 o superior.
- Metrics Server desplegado en el cluster de Kubernetes.
- Kubectl instalado en tu workstation.
Escalado con métricas de recursos por contenedor en acción
- Despliega un deployment de ejemplo con varios contenedores usando el siguiente manifiesto.
cpu-stressores el contenedor principal y está diseñado para simular estrés de CPU en pods de Kubernetes. Consulta el repo de GitHub para más detalles sobre la herramientacpu-stressor.log-generatores un contenedor secundario de ejemplo dentro del mismo pod.
cat <<EOF | kubectl apply -f -
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: crm-scaling-demo
labels:
app: crm-scaling-demo
spec:
selector:
matchLabels:
app: crm-scaling-demo
template:
metadata:
labels:
app: crm-scaling-demo
spec:
containers:
- name: cpu-stressor
image: narmidm/k8s-pod-cpu-stressor:1.0.0
args:
- "-cpu=0.5"
- "-duration=3600s"
resources:
limits:
cpu: "200m"
requests:
cpu: "100m"
- name: log-generator
image: busybox:1.28
args: [/bin/sh, -c,\
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
resources:
requests:
cpu: "100m"
EOF

Pod de ejemplo y uso de recursos en todos los contenedores del pod
- Crea un recurso
HorizontalPodAutoscalerque escale según el uso de CPU del contenedorcpu-stressor, en lugar de las métricas del pod.
cat <<EOF | kubectl apply -f -
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: crm-scaling-demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: crm-scaling-demo
minReplicas: 1
maxReplicas: 10
metrics:
- type: ContainerResource #new-metrics-source
containerResource:
name: cpu
container: cpu-stressor #container-name
target:
type: Utilization
averageUtilization: 50
EOF
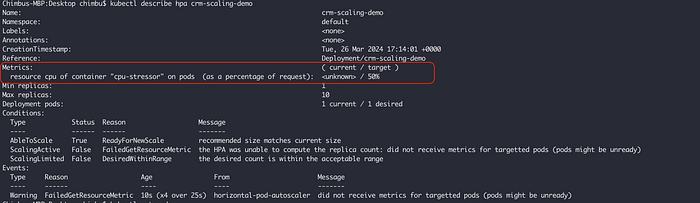
Configuración de HPA de ejemplo basada en las métricas del contenedor cpu-stressor
En el ejemplo anterior, el controlador del HPA escala el objetivo para que la utilización promedio de CPU del contenedor cpu-stressor en todos los pods sea del 50%.
- Espera a que el contenedor
cpu-stressorsimule el estrés de CPU y verás cómo el HPA recalcula la cantidad de pods según la utilización de CPU del contenedorcpu-stressor.
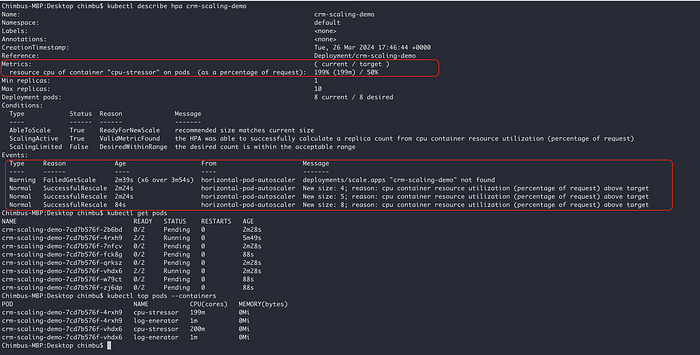
Escalado de HPA de ejemplo basado en las métricas del contenedor cpu-stressor
Demo de escalado del HPA con métricas de recursos por contenedor
La captura y el video demo muestran un escalado exitoso del HPA a partir del contenedor cpu-stressor en un pod con varios contenedores 🚀.
Con las métricas de recursos por contenedor ya estables en Kubernetes v1.30, puedes alcanzar un nuevo nivel de precisión en el autoscaling horizontal de pods y asegurar el mejor rendimiento de tus aplicaciones.
Espero que este post te haya resultado útil. Para más información, consulta los siguientes recursos: