Introdução
Os chips ARM são a escolha preferida para celulares e pequenos dispositivos desde o lançamento do Apple Newton, em 1993, e hoje estão presentes na maioria dos smartphones que usamos. Recentemente, esses chips chegaram a um novo território: a computação em nuvem. O AWS Graviton, lançado pela Amazon em 2018, foi o primeiro processador ARM projetado por uma grande provedora de nuvem.
O modelo de foundry, um modelo de negócio bem-sucedido para projetar e fabricar circuitos integrados, foi adaptado para criar CPUs ARM voltadas a servidores em nuvem. Veja como isso costuma funcionar:
- A ARM Holdings projeta SIP Cores baseados na arquitetura RISC e os licencia para outras empresas.
- Os hyperscalers (Amazon, Google e Azure), que também são fabricantes de semicondutores fabless, implementam esses SIP cores, adicionam customizações e geram tape-outs de CPUs.
- Esses tape-outs são então enviados para uma foundry pure-play de semicondutores, que faz a fabricação propriamente dita do dispositivo.
A série Neoverse da ARM é uma família de CPUs projetada especificamente para workloads de computação em nuvem, HPC e IA.
Neste post, vamos avaliar duas implementações da arquitetura Neoverse V2: AWS Graviton 4 e Google Axion. Deixamos o Azure Cobalt 100 de fora desta comparação porque ele utiliza uma variante um pouco diferente da arquitetura Neoverse: a Neoverse N.
O conjunto de testes
Aplicações web estão entre os workloads mais implantados em nuvem. Para avaliar o desempenho das CPUs Graviton 4 e Axion em workloads de aplicações web, vamos usar o TechEmpower Framework Benchmarks (TFB). Ele traz testes para diversas linguagens de programação e frameworks, mas, para simplificar, vamos usar o famoso framework reativo baseado em JVM, o Vert.x.
Os testes do TFB avaliam o desempenho de frameworks web em pontos como roteamento de requisições, manipulação de JSON, throughput e interações com banco de dados (mapeamento ORM, cache e pooling de conexões). O TFB exige três máquinas virtuais para conduzir esses testes: um servidor de aplicação para hospedar o framework web, um servidor de banco de dados e um gerador de carga.
Configuração da infraestrutura
Na AWS, usamos 3 VMs R8g.xlarge (4 vCPU, 32 GiB de memória) com 20 GB (gp3 SSD). Todas foram implantadas em uma única AZ para minimizar a latência de rede entre AZs.
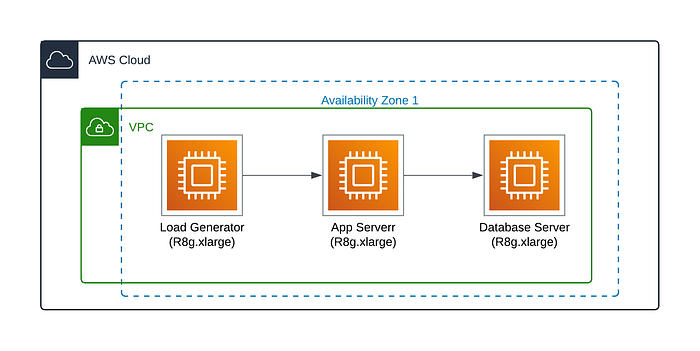
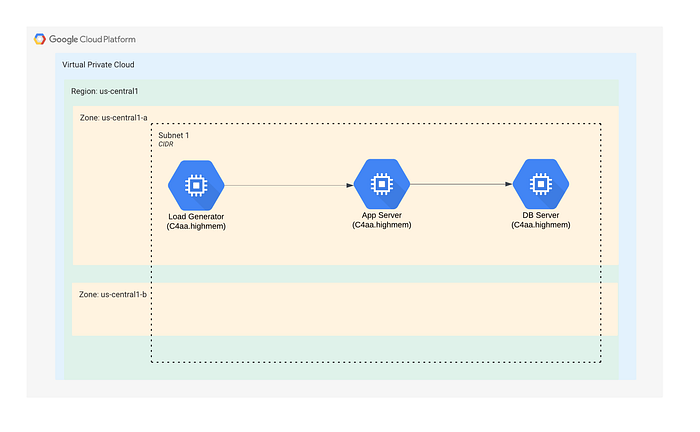
No GCP, seguimos a mesma lógica: C4A-highmem-4 (4 vCPU, 32 GiB de memória) e 20 GB de SSD. Todas as VMs foram implantadas em uma única AZ.
Resultados do benchmark
O TFB usa uma ferramenta poderosa chamada wrk para simular cargas reais nos servidores de aplicação. Veja como funciona:
- O wrk gera diferentes níveis de requisições simultâneas, imitando intensidades variadas de tráfego de usuários.
- O benchmark registra o número de linhas retornadas em cada cenário de teste.
- Quanto maior a contagem de linhas, melhor o desempenho da CPU, mostrando a capacidade do processador de lidar com mais dados sob pressão.
A seguir, os resultados de cada caso de teste (quanto maior, melhor):
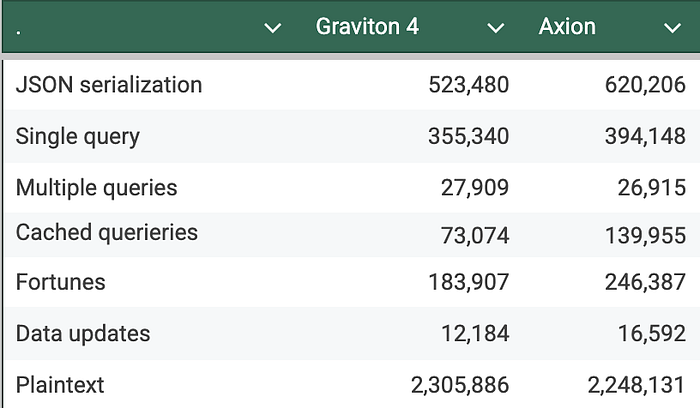
Números maiores indicam desempenho superior, mostrando a capacidade do processador de lidar com mais dados sob pressão (quanto maior, melhor).
O gráfico abaixo apresenta esses números em barras, destacando a diferença percentual de desempenho entre Graviton 4 e Axion.
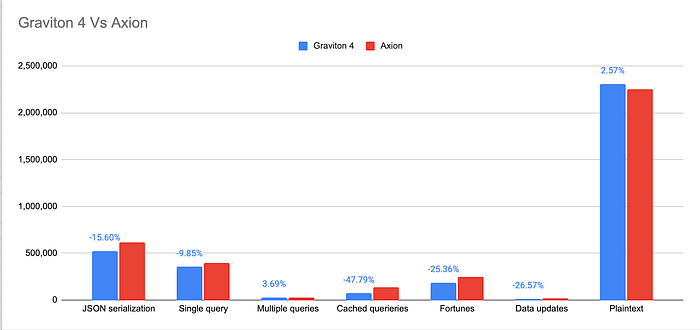
O gráfico evidencia a diferença percentual de desempenho entre Graviton 4 e Axion (quanto maior, melhor).
Conclusão
Os resultados deixam claro que o Axion, chip ARM mais recente do GCP, supera o AWS Graviton em 5 dos 7 casos de teste. A vantagem do Axion vai de 9,85% a impressionantes 47,79% em relação ao Graviton 4. Em apenas dois casos (plaintext e multiple queries), o Graviton tem desempenho superior, ficando à frente do Axion em 2,57% e 3,69%. Vale a pena aprofundar a análise para definir o chip ideal de acordo com os requisitos específicos da aplicação e o custo.
Fale com a gente na DoiT. Com um time formado exclusivamente por engenheiros sêniores, somos especialistas em consultoria avançada de nuvem, design de arquitetura, orientação em debugging e serviços de consultoria.