プログラミングを始めたばかりの頃は「コメントはできるだけたくさん書きなさい」と教わるものです。ところがしばらくすると、今度は「コメントは控えめに」と説く記事に出会います。混乱しますよね。本記事では、いつコメントを書くべきで、いつ避けるべきかをはっきりさせていきます。
原則はシンプルです。ソフトウェアについて文書化した内容が真実であることを、できるだけ早い段階で言語とランタイムに保証させましょう。

頼れる執行役たち
まずはドキュメントのない関数からスタートし、私が普段実装する順序で段階的に整えていきます。最初は基本のキ、次にドキュメントが真実を語っていることを自動的に保証する仕組み、最後に自動化が使えない場合の弱めのドキュメント手段、という流れです。
1\. ドキュメントなし
まずはこのシンプルな関数、p!(階乗)から始めましょう。プログラミングの基礎演習でおなじみのものです。例はPythonですが、基本的に他の言語にも当てはまります。
def fact(p):
ret = 1
if x == 0:
return 1
for i in range(1, x + 1):
ret *= i
return ret
ここで、こんなコメントを足したくなるかもしれません。
""" This is the factorial """
ですが、コメントは読まれないことが多く、しかもまともな命名さえできていれば不要です。
2\. 命名
関数を次のように変えます。
def factorial(p):...
ドキュメントは、横に並べて貼り付けるものではなく、実行されるコードそのものに組み込まれた状態になりました。あなたの関数を使いたい人は、この名前を必ず目にすることになります。これは、関数を短く、単一の目的に保つべき理由のひとつでもあります。そうすれば、関数名がコードのすぐ近くにあり、その内容を端的に表せるからです。
読み手の理解を助ける他の工夫(適切な箇所でprivateメンバーを使うなど)も、立派なドキュメントの一形態です。
次に、引数名を n に変えて、整数であることをユーザーに思い出させましょう。
def factorial(n):...
というのも、階乗は整数についてしか定義されていませんが、非整数にも拡張できるからです。ガンマ関数は、いわば階乗の拡張版にあたります。
上級ユーザーは「もしかして今回の実装でもそれを使っているのでは?」と疑うかもしれません。それも当然で、たとえば scipy.special.factorial は、ガンマ補間を用いて非整数の float 入力に対しても答えを返します。今回はそういう関数ではない、と明確にしておく必要があります。
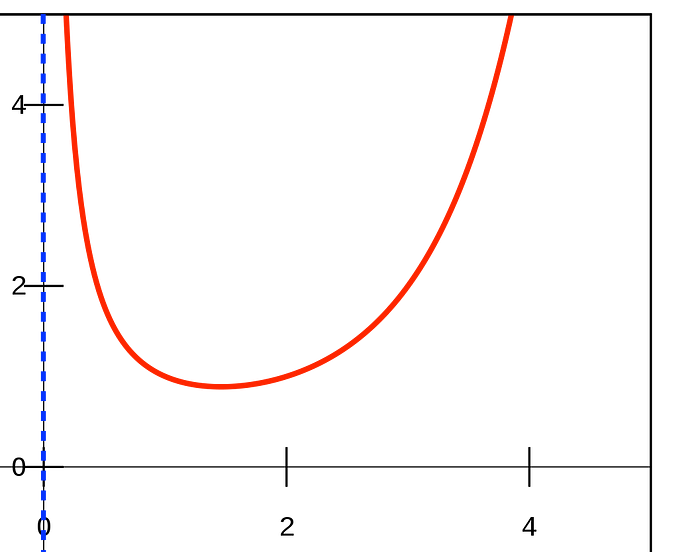
ガンマ関数は、ほぼすべての実数(および複素数)に階乗を拡張します。
3\. 型ヒント
引数名はある種のコメントですし、それが int であることをコメントで書くこともできます(実際に scipy.special.factorial はそうしています)。ですが、引数が整数であることを読み手に伝えるなら、もっと良い方法があります。型ヒントです。
def factorial3(n: int) -> int:...
Pythonの開発ツールは、ほとんどのエラーを警告してくれます。原則は「コンピュータに代わりにドキュメント化させ、人間の脳への依存を最小限にする」ことです。たとえば、実装が float の3.0 を int として受け付けない場合、型ヒントがその場で文書化してくれます。手書きのコメントでは見落としかねないことです。
コメントは古びることもあれば、まったくの誤りであることもあります。たとえば scipy.special.factorial(SciPyを貶めるつもりはありません。素晴らしいライブラリです!)はコメントに「n : int」と書いていますが、実際には float も受け付け、ガンマ関数に従った値まで返してきます。
コンパイル時の型付け
例はPythonですが、JavaやC++のようにコンパイル時に型付けを行う言語を使っているなら、型を宣言した時点で多くのミスを開発時にコンパイラがブロックしてくれます。この「ドキュメント」が正確であることを、できる限り早い段階で保証してくれるわけです。
とはいえ、入力が負数でないことのような細かな制約を捕捉するなら、より高度な型システムを備えた言語でない限り、アサーションのほうが適しています。
4\. アサーション、例外、または事前・事後条件
型ヒントをさらに一歩進めることができます。値が整数であること、そして非負であることをアサートするのです。そうすれば、開発ツールがそっと教えてくれるだけでなく、ランタイムが発生した瞬間にミスを止めてくれます。
def factorial4(n: int) -> int:
assert isinstance(n, int), f"{n} is not an integer and so unsupported."
assert n >= 0, f"{n} is negative and so unsupported."
...
エラーの投げ方にはいくつかの選択肢があります。
こうしたミスをそのまま通す意味はないので、アサーションは有効のままにしておきましょう。代わりに ValueError を投げてもかまいません。事前・事後条件(構造化されたアサーションの一種)による契約プログラミングをサポートする言語やライブラリを使っているなら、それでも目的は果たせます。
@icontract.require(lambda n: isinstance(n, int) and n>=0, "n must be a nonnegative integer")
def factorial_precondition(n: int) -> int:
return __iterative_factorial(n)
ここまで来ると、コンピュータが本当に私たちの仕事をチェックしてくれている状態です。しかも、アサーションやその他の例外にはもうひとつの価値があります。決して間違うことのないドキュメントになる、という点です。読み手は、アサーションが述べていることが真実だと確信できます。
例の scipy.special.factorial に戻ると、コメントには「n < 0 の場合、戻り値は0」とあります。
厳密にはこの実装ではそのとおりですが、階乗が負数では未定義であることを知っているユーザーには紛らわしい説明です。階乗を拡張したガンマ関数でさえ、実数や複素数全体で定義されているとはいえ、負の整数では未定義です。エラーを投げて、何が許され何が許されないかを明確にするほうがはるかに良いでしょう。
5\. ユニットテスト
ユニットテストはアサーションに似ています。開発時にシステムが期待どおりに動くかを確認するものです。ドキュメントとしてはアサーションよりも弱く、コードからファイル的にも実行タイミング的にも離れているため、他の開発者に読まれにくいのが難点です。
とはいえ、本来あるべき姿として開発者がテストを継続的に走らせていれば、コメントを掘り返さなくともすぐにエラーに気づけます。
たとえば、私たちのシンプルな反復実装の階乗には欠陥があります!負の値に対して 1 を返してしまうのです。これは階乗としても、ガンマ拡張としても明らかに誤りです。次のテストは、エラーが返ることを期待しているのに、残念ながら値が返ってきてしまうことを示します。
def test_factorial():
with pytest.raises(Exception):
factorial(-2)
doctestを使えば、コメントの中に小さなユニットテストを埋め込むこともできます。これはPython 3の組み込み機能です。テストをコードのできる限り近くに置けるので、ドキュメントとしては最も効果を発揮します(一方で、見た目がごちゃつくこともあります)。
def factorial_doctest(n) -> int:
"""
Run this with python -m doctest -v factorial.py
>>> factorial_doctest(3)
>>> factorial_doctest(0)
>>> factorial_doctest(1.5)
Traceback (most recent call last):
...
TypeError: 'float' object cannot be interpreted as an integer
"""
return __iterative_factorial(n)
同様に、結合テストはコードからさらに離れており、コードのドキュメント化には不向きです。代わりに、システム全体のふるまいを文書化するものになります。
6\. ロギング
悪いことが起きそうで、それを事前に防ぐ手立てがないなら、せめてログに残しましょう。ここでもSciPyの話に戻ります。
float を渡すと、標準エラーに次の出力が現れます。
DeprecationWarning: Using factorial() with floats is deprecated
どうやら最初はガンマベースの実装を採用していたものの、後になって整数のみをサポートすべきだと気づき、入力を int に制限したかったようです。依存するアプリケーションの都合でそれができなかったため、せめて読まれそうな場所に警告を出力することにしたのでしょう。開発者はドキュメントを読まないことはあっても、問題に直面したときにはログを読むものです。
7\. コメント
ようやく最後から2番目の手段、コメントにたどり着きました。コメントにも出番はありますが、私の経験では次の3つのケースに限られます。
a. 公開APIはインラインコメントで文書化し、PythonならDoxygen、JavaならJavadocsなどでHTMLを生成すべきです。コメントはタグで構造化しましょう。「コンピュータが構造をチェックできるなら、チェックさせるべき」という原則に従ってのことです。
Pythonでの構造化コメントの例です。
:param n: A nonnegative integer
:return: The product of all integers from 1 up to and including n; or for 0, return 1.
ただし、関数が公開APIでない場合は、こうした構造化フィールドの使用は控えめに。これらのコメントは、何か特殊な事項について特定のメッセージを伝えるためのものであり、使い方のあらゆる側面を几帳面に文書化するためのものではありません。
b. 意外な事実は文書化すべきです。たとえば「0の階乗は1と定義されている」ことは、ユーザーにとっては意外かもしれません。「1からnまでの全数の積」という階乗の定義にうまく当てはまらないように見えるからです。同様に、奇妙な回避策や見苦しいハックも、コードにコメントしておくべきです。
c. アルゴリズムには名前を付けるべきです。コンピュータはどのアルゴリズムが使われているかを示したり保証したりはできませんし、読み手も一目で識別できるとは限らないからです。たとえば階乗は、乗算で計算することもできれば、ガンマ関数のさまざまなアルゴリズムで近似することもできます。シビアな数値計算用途のユーザーにとっては、ぜひ知っておきたい情報でしょう。
def factorial(n: int) -> int:
"""
This is a simple iterative implementation of factorial.
The input must be a non-negative integer.
Note that the factorial of zero is defined as 1.
"""
8\. 外部ドキュメント
コメントは最後から2番目の手段でした。外部ドキュメントは本当に最後の手段です。RTFM(マニュアルを読め)は素晴らしいスローガンですが、実際にマニュアルを読む人はほとんどいません。コードから遠く離れているため、すぐに陳腐化してしまうからです。それでも、機能の概要やチュートリアルが必要なら、コードとは別管理のドキュメントに記す手もあります。
ただし要注意です。絶えず変化するコードに合わせたいなら、これらのドキュメントを継続的に見直し、読み返さなければなりません。
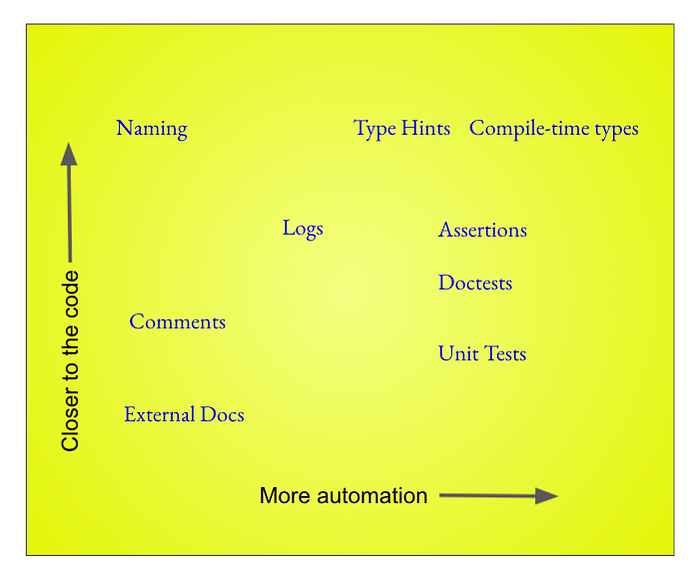
コードに近く、より自動化されているほうが望ましいとはいえ、どの手段にもそれぞれの役割があります。
ドキュメントは真実を語るべきです。あなたの言語ツールやランタイムには、信頼性を担保する手段が数多くあります。それを活用しましょう。ドキュメントはコードのできる限り近くに置き、その正確性を自動的に強制する仕組みを、開発プロセスのできるだけ早い段階で取り入れましょう。
各種実装の実行可能なコードとユニットテストはこちらにあります: https://github.com/doitintl/commenting
最新情報は DoiT Engineering Blog、 DoiT Linkedin Channel、 DoiT Twitter Channel でフォローしてください。採用情報は https://careers.doit-intl.com をご覧ください。