そもそもラベルとは?
GCPの公式ドキュメントでは、ラベルは「関連性のあるリソース同士をまとめてグループ化するための軽量な手段」と定義されています。
定義としてはこれで十分ですが、より重要なのは「何のために使うのか」という点です。
リソースにラベルを付ける主な目的は、特定のリソースのコストを請求データから簡単に追跡できるようにすることです。デフォルトでは、請求書内の各サービスはひとまとめの明細として表示されてしまいます。
たとえば、Compute Engineインスタンスを稼働させた際の請求明細は、次のように表示されます。「Compute Engine Small Instance with 1 VCPU running in Americas: 15342.56 Hours.」
一見すると単純そうですが、1ヶ月の平均時間が730時間しかないことを思い出すと話が変わってきます。つまり、その月に複数のインスタンスが稼働していたわけですが、何台だったのでしょうか? また、それぞれがどれくらいの時間、どのプロジェクトで稼働していたのでしょうか? GCPコンソールの請求レポートを見ても、それ以上の情報はほとんど得られません。
こうしたデータを、Googleが請求書やコンソールに表示する数値だけから割り出すのはほぼ不可能です。そこで活躍するのがラベルです。
プロジェクトでラベルを使うと、請求レポートは次のように表示されます。
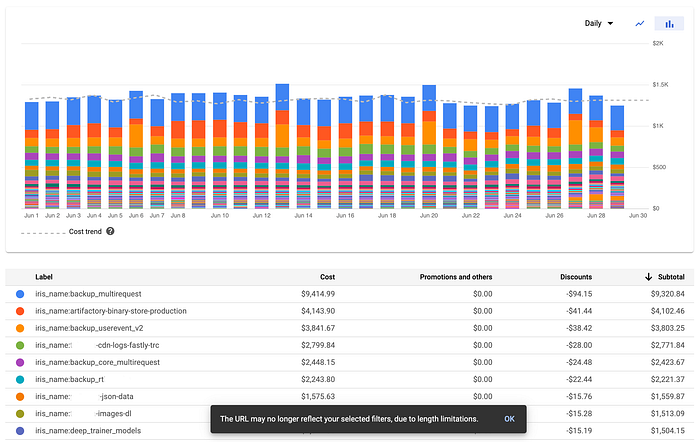
GCP請求レポート(一部の名称は削除済み)
ラベルごとに内訳が分かれていて、格段に読みやすくなっているのがわかります。ラベル中のiris_nameについては、本記事の後半で説明します。
ラベルとタグの違い
まず押さえておきたいのが、GCPにおけるラベル(labels)とタグ(tags)の違いです。
少し前までは両者はほぼ1対1の関係にありましたが、GCPの進化に伴って現在では別の概念として扱われています。今のタグは、ネットワークポリシーを適用する目的でリソースをグループ化する仕組みであり、一方のラベルは請求や検索(および将来的にはさらに別の用途)のためにリソースをグループ化する仕組みです。
たとえば、ファイアウォールルールを作成してターゲットタグを設定すると、同じネットワークタグが付いているCompute Engineインスタンスなどのリソースに、そのルールが適用されます。多くの方が気づく一番の違いは用語の使い分けです。GCPでは現在、「タグ」はネットワークタグ(ファイアウォールルールでいうターゲットタグ)を指し、「ラベル」はラベルを指します。以前はその両方をまとめて「タグ」と呼んでいました。
新しい用語が定着するまでには時間がかかるかもしれません。GCPで「タグ付けされている」と聞いたときは、それが本当にタグなのかラベルなのか、いったん立ち止まって確認しましょう。長年「タグを付ける」という言い方をしてきたぶん、ラベルを指すときに切り替えるのは簡単ではないはずです。
DoiTコンソールとCloud Analytics
GCPの請求やコスト管理において、知る人ぞ知る強力なツールの1つが、DoiTコンソールのCloud Analyticsです。これはDoiT Internationalが提供する、コストの可視化と最適化のためのツールです。
レポート機能を使えば、Google Cloud Platformの請求状況をリアルタイムで把握し、予算管理、コスト配分の設定、予算超過やコスト異常時のアラート受信、さらにさまざまなコスト最適化施策の検討まで行えます。
レポートを使うことで、Google Cloudのコストに対する可視性はさらに高まり、次のようなメリットが得られます。
- 最大36ヶ月分の履歴データ(標準は3〜6ヶ月)
- レポートの読み込み・更新時間が100倍高速
- ユーザーラベル・システムラベルともに無制限(標準ではどちらか一方のみ)
- SUDsやCUDsといったクレジットに関するレポートにも対応
- ビルトインレポートを標準搭載
- はるかに豊富なチャートタイプ
- モバイル対応のレポート
- 定期的なレポート更新をメールやSlackで受信可能
注:本記事の公開以降、DoiTコンソールには非常に多くの新機能が追加されているため、一部の画像は古くなっている可能性があります。
DoiTコンソールでは、すぐに使える定義済みレポートのセットを標準で提供しています。これらのレポートは組織全体で共有されるため、自分とチームが同じ情報を手間なく共有できます。
Cloud Reportsはピボットテーブルと同じ発想で、任意のディメンションと指標を組み合わせて柔軟にレポートを作成できます。
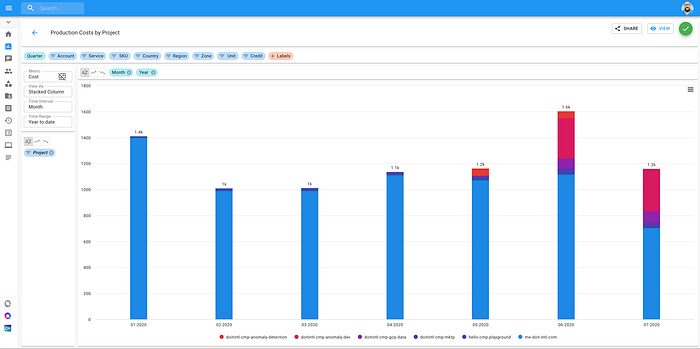
ディメンションと指標をドラッグするだけでCloud Reportsを設定
リソースにラベルを付けている場合や、Iris3でラベルを自動生成している場合は、バケット単位でのGoogle Cloud Storageコストなど、請求情報から有用なインサイトを引き出せます。
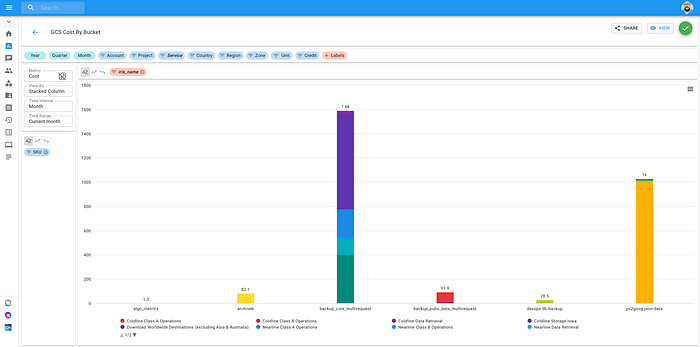
バケット単位のGCSコスト
請求データを時間単位の指標として確認できるため、直近のデプロイや構成変更に起因する請求の異常やスパイクをすぐに発見できます。
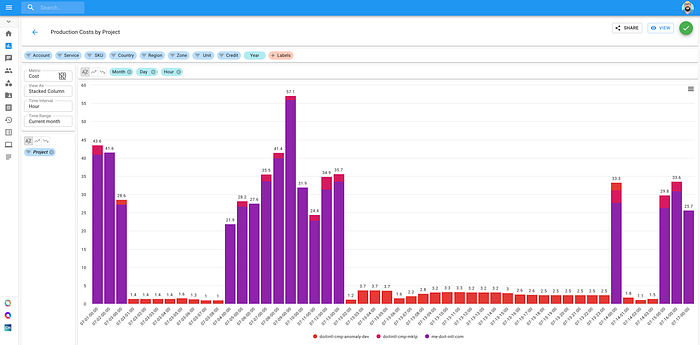
時間単位のデータでクラウド環境の変化を簡単に追跡
追加費用なしでDoiTコンソール(およびその他多数のツール)を利用してみたい方は、こちらからお問い合わせのうえ、追加費用なしでDoiT Internationalのお客様になる方法をぜひご確認ください。
ラベルのベストプラクティス
以下は、DoiT InternationalのCustomer Reliability Engineeringチームが、GCPでのラベル運用についてまとめたベストプラクティスです。
ラベルを設定する前に、まずはラベルの制約と適用可能な対象を理解しておくのが望ましいでしょう。本記事の執筆後にも仕様が変更される可能性が高いため、まずGoogleの公式ドキュメントに目を通すことをおすすめします。
すべての製品がラベルに対応しているわけではありませんが、ドキュメントに明記されていなくても対応している製品は数多くあります。サービスのインスタンス作成・編集ページを確認するのが、ラベル対応の有無を判断する一番確実な方法です。
必ずラベルを付ける
新しいCompute Engineインスタンスや、それをベースにしたイメージを作成する際、ついラベルを付け忘れてしまい、経理から請求書のある支出について問い合わせが来て初めて気づく――そんなことがしばしば起こります。
これを防ぐには、リソース作成時に必ずラベルを付ける運用をワークフローに組み込み、自動化されたリソース作成プロセスでも確実に実行されるようにしましょう。
ラベル付け自動化ツールを活用する
前述のヒントに関連して、Iris3はDoiTが開発したオープンソースツールで、リソースの作成と同時に自動でラベルを付与してくれます。最近リライトされたばかりです。これを使えば、リソースへのラベル付け漏れを心配する必要がなくなります。
使いたいリソースタイプがまだ未対応の場合でも、追加のリソースタイプに対応するようカスタマイズすることが可能です。
必要なものすべてにラベルを付ける
ラベルはキーと値のペアです。これを活かして、必要な情報をどんどんラベルに盛り込みましょう。
ラベルの活用例をいくつかご紹介します。
環境名
リソースを開発・ステージング・テスト・本番などのラベルで区別しておくと安心です。後から本番環境のリソースだけを請求レポート用に検索するのが格段に楽になります。
ロール
Webサーバーとして動くCompute Engineリソース群、GKEクラスター内のリソース群、データベースサーバー用のリソースなど、それぞれの役割に応じてラベルを付けましょう。
アプリケーション名 ラベルにアプリケーション名を入れておくと、関連するビジネスプロジェクトやアプリケーション単位でリソースをまとめやすくなり、アプリケーションごとのコストも把握しやすくなります。
リージョン名 アプリケーションやプロジェクトが複数リージョンにまたがっている場合、リージョン値を加えておくと後で並べ替えがしやすくなります。GCPのリージョン名でも、アプリケーション内で独自に定義した論理リージョンでも、あるいはその両方をラベルにしても構いません。
リソース作成者 作成者名をラベルに入れておけば、保管されているとは限らない監査ログを掘り起こさなくても、誰がどのリソースを作ったかをすぐに特定できます。
オーナーまたはメンテナー オーナーやメンテナーの名前をラベルに入れておくと、問題や疑問が生じたときに誰に連絡すべきかがすぐにわかります。リソースを所有・保守するチーム名を入れるのが一般的な例です。
コスト・請求・予算コード 組織によっては、支出や予算ごとに固有のコードを設けている場合があります。これをラベルに加えておけば、請求担当者や監査人がコストを追跡しやすくなります。
部門
リソースが特定の部門に属している場合、ラベルに部門名を加えておくと、後から部門単位でコストを追いやすくなります。
バケット名(Google Cloud Storageのみ) GCPの請求レポートや請求書を見たことのある方ならご存じのとおり、ストレージバケットはすべて1つの明細にまとめられてしまいます。各バケットのコストを知りたいときには厄介ですが、各バケットにバケット名のラベルを付けておけば、明細を分けて表示できるようになります。
関連リソース名 あるリソースが別のリソースに紐づいている場合は、関連先リソース名のラベルを付けておくとよいでしょう。たとえば、Compute EngineインスタンスやDataprocクラスターに紐づく永続ディスク、Compute Engineマネージドインスタンスグループに紐づく外部IPなどが好例です。
データ分類 やや大きなテーマですが、バケットやBigQueryデータセット内に分類が必要なデータがある場合は、それを示すラベルを付けましょう。HIPAAやPCIなどの規制対象データや暗号化データが代表例です。こうしたリソースに事前にラベルを付けておけば、経営層から「PHI(保護対象保健情報)の保管に毎月いくらかかっているのか」と聞かれたときにも、すぐ回答できます。
リソースの状態
アクティブ、削除保留中、無効など、リソースの状態をラベルに付けておくと、特定の状態にあるリソースにいくら課金されているかをひと目で確認できます。
フォルダまたは組織名 組織構造でフォルダや組織単位を活用しているなら、それぞれにラベルを付けておきましょう。組織やフォルダごとのコストを後から確認できるようになります。
このテーマやGCPの組織構造設計について深く知りたい方は、同僚が執筆したこちらの記事をぜひお読みください。
ラベルを標準化する
各リソースに付ける標準ラベルのセットを定め、それを徹底的に運用しましょう。リソースタイプごとに標準ラベルを用意するのも有効です。これだけで、リソースの検索や、請求レポート上でのリソース群の追跡が格段にしやすくなります。
ここでもIris3で自動化すれば、決めたルールを維持しやすくなります。
フィルターとラベルでリソースを検索する
コンソール各所のフィルターバーで「labels」と入力し始めると、ドロップダウンに候補が表示されます。それを選択し、コロンの後にラベル名を打ち込むとオートコンプリートが効き、特定のラベルでフィルタリングできます。
なお、本記事の執筆時点では、Cloud Storageのページではこの機能はまだ動作しません。
GKEではKubernetesラベルを使う
GKEでは、Kubernetesラベル機能(クラスター作成時のメタデータページにあります)を使って、クラスター内の各ノードにラベルを付けられます。
ヒント:Kubernetes側ではセレクターを使ってこれらのノードを指定できます。なお、これはGKEを使う場合のみ有効で、スタンドアロンのクラスターには適用されません。
BigQueryの請求クエリでラベルを使う
BigQueryを請求データのシンクとして利用したことがあるなら、生成されるテーブルにlabelsレコードがあることに気づいているはずです。サービスに付けたラベルはすべて、その行に対応するリソースのレコードに反映されます。これを活用すれば、BigQueryでより踏み込んだデータ分析が可能になります。
キューにもラベルを付ける
Pub/Subをキューやワークフローの一部として利用しているなら、トピックにラベルを付けて、それがどのアプリケーションやワークフローに属するのかを明示しましょう。これは特にPub/Subのヘビーユーザーにとって、見落とされがちなコストです。なお、本記事の執筆時点では、Pub/Sub Liteはラベルに対応していません。
ラベルポリシーを最新の状態に保つ
新しいプロジェクトを更新・展開するときや、GCPで新しいサービスを使い始めるときは、そのサービスがラベルに対応しているかを確認しましょう。対応している場合は、ラベルポリシーを更新して取り込むか、自動化のためにIris3に追加しておきましょう。