









Kaggle Days is (almost) officially the most interesting event to meet, learn and compete against the most talented data scientists worldwide. And this is how we won it.
The city of Paris hosted this January (2019) the 2nd ever Kaggle Days event. More than 200 data scientists from all around the world gathered to learn, share knowledge and eventually compete against each other in a 11 hours in-class Kaggle competition that took place during the conference. This blog post describes our solution to the competition, that won us the 3rd place.
Predicting Sales of LMVH’s Luxurious Products
Challengers were provided with data from the first seven days of Louis Vuitton products after their launch on www.louisvuitton.com. The goal was to forecast sales on each of the three months following the launch. Additional data included product descriptions, sales statistics, social media, website navigation, and image data.
Strategy
Like in many of our past Kaggle competitions we followed simple tactics:
- Dumb features complex models — build simple features and let the ML models “understand” the complex interactions between them.
- Embrace diversity — train many models and ensemble best leaderboard performing models with the least overlap in their errors.
- Teamwork — each team member has a well defined responsibility: the Feature-Extractor, the Modeler and the Integrator.
Baseline
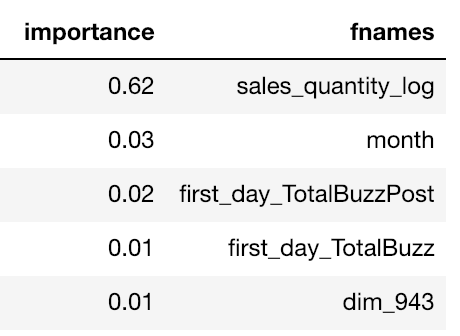
Before even looking at the data we stood on the shoulders of giants and used Kaggle Days’ team baseline script that included numerous features. We ran a simple Random Forest model of no more that 100 trees on the entire train data, just to see the importance of each feature. The results came as an absolute surprise as the log of the first 7 days’ sales received X20 larger importance score compared to all other features. This piece of information allowed us to control the variance of the generated models to some extent.
Formulating the business question
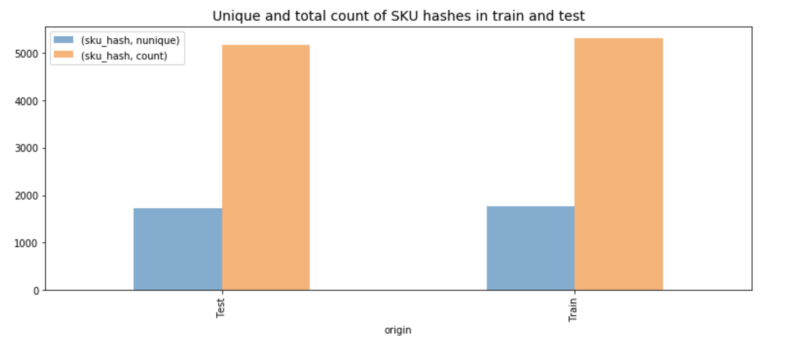
Diving into the data, we discovered that someone had made a good job splitting the it. The training data consisted of ~1700 unique products while the test included almost the same amount different products. It made us think of the problem as follows: assuming a specific product, let’s say a women bracelet, was sold x times on the first week after it’s launch and some m1, m2, m3 on the consecutive months, How much will be sold given a similar item?
Ignoring trends — since the data was relative to the first week of launch and didn’t include the Gregorian month we neglected seasonal trends paid less attention to social media trends. Basically it came down to the question of product similarity. It’s worth mentioning that Mikel Bober-Irizar managed to estimate the relative reduction in sales during the test period, thus improving the score via technique we call MLE — Maximum Leaderboard Estimation.
How to model product similarity
- Categories — the products were categorized by human experts to different types such as leather goods and daily bags. These features were extremely valuable in understanding the similarity between different products’ sales. Not only that these features reflect how a human would perceive these items in a passive way but also actively affect the sales because they determine the position of the item on the website and the way it is presented to customers.
- Text — charechtirazing the feature using its text by applying TF-IDF and PCA over the features.
- Image vectors — the image features were extracted by using Google’s Vision API. This API utilizes neural networks trained on very generic datasets like ImageNet — not at all useful for distinguishing between two luxurious casual hand bags. Hence, we ignored these features.
- Click-through rate— Data from the websites traffic included page views and item clicks. from this we extracted the average clickthrough rate and used it as a feature.
Models
Since the data included valuable categorical features, it was important to use a library that can leverage categorical features in an efficient way. XGBoost doesn’t have a built-in categorical features mechanism vs LighGBM and Catboost. Catboost took too long to process so we ended up running LighGBM with GBDT and Random Forest as boosting methods. Neural networks failed to converge due to the relatively small amount of data.
So, why do we say it’s overfitting?
Assuming we were consulting LMVH on how to increase sales, we would have applied a somewhat different approach. For example, LMHV could perform A/B testing on the most important features like the categorization or textual descriptions of the products to examine whether augmenting them would affect sales. Nevertheless, when striving to win a Kaggle competition our only goal is to best fit our predictions to the test set.
Machines and environments
All code ran on a preemptable Google Cloud Deep Learning VM with a n1-highmem-8 (8 vCPUs, 52GB RAM, 0.1$ USD / Hr) instance. The machine was located in us-central area, thus it had high availability during competition hours, since we were in Europe.
Experience
While Kaggle is an amazing platform to share knowledge and challenge yourself in very diverse and difficult competitions, Kaggle days adds an important layer to this community: in-person interaction. We had a fantastic time meeting fellow data scientist from all around the world and learn that we all share a common dream: Overfit the test data.
Notebook code here on Github | Kaggle profile: Gad Benram



